Experquiz propose deux types de questions qui permettent d’évaluer et mesurer les soft-skills. Ces questions ont la particularité de ne pas avoir de bonnes ou de mauvaises réponses :
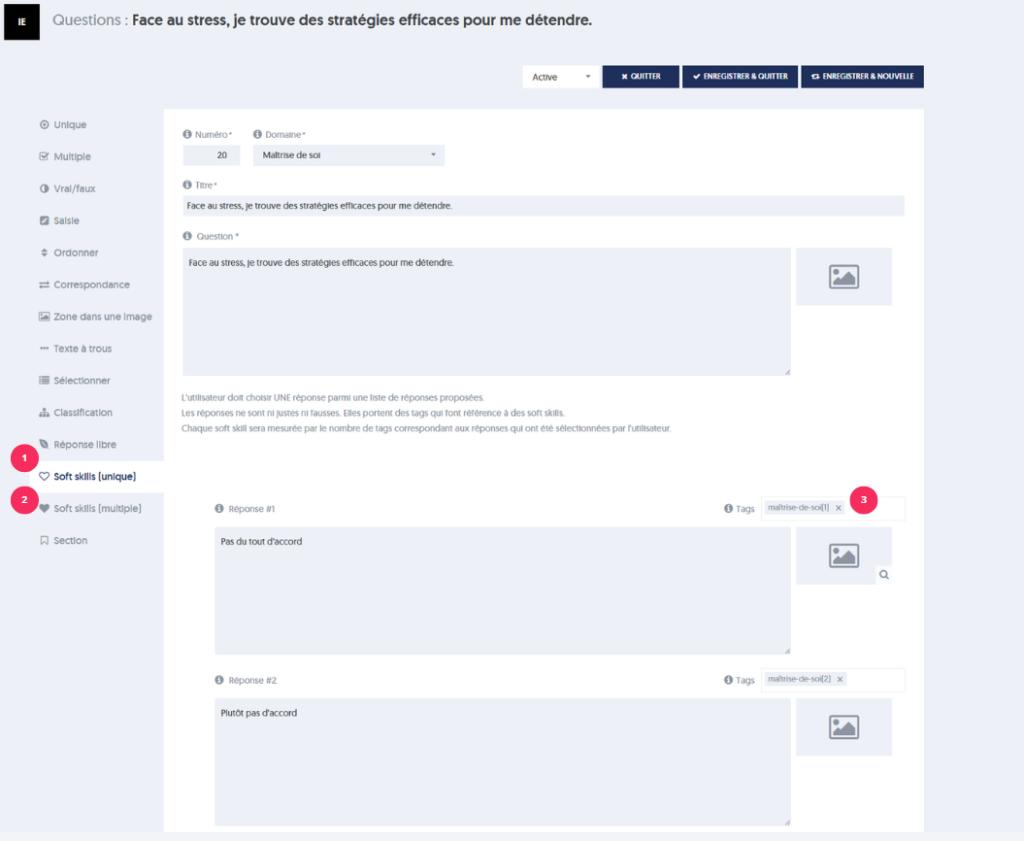
[1] Les soft-skills uniques : l’utilisateur doit choisir UNE réponse parmi une liste de réponses proposées.
[2] Les soft-skills multiples : l’utilisateur doit choisir PLUSIEURS réponses parmi une liste de réponses proposées.
[3] Chaque réponse est associée à un tag qui fait référence à des soft-skills.
Chaque compétence douce sera mesurée par le nombre de tags correspondant aux réponses qui ont été sélectionnées par l’utilisateur.
Pour en savoir plus sur la gestion des tags des questions de type « soft-skills », vous pouvez consulter notre page dédiée.
Comme pour les autres types de questions, il est possible de mélanger les réponses, d’ajouter une explication et une règle en cliquant sur le bouton « Plus de paramètres » :
Côté apprenant, l’affichage est le même que pour une question QCM classique. Un questionnaire peut comporter à la fois des questions classiques et des questions de type soft-skills..
Illustration avec le soft-skill à choix unique
À la question : « comment réagiriez-vous si l’on vous proposait d’accompagner une équipe scientifique pendant 3 mois dans l’Antarctique ?« , nous avons adjoints les propositions de réponses suivantes avec les tags qui les accompagnent :
P1 : « 3 mois avec une dizaine d »‘inconnus, dans la nuit et à -80°C, jamais ! » avec les tags « casanier« , »instinctif«
P2 : « Génial, une aventure qui va me sortir de mes habitudes, quand part-on ? » avec les tags « instinctif« , « audacieux« , »curieux«
P3 : « Pourquoi pas? Apprendre demande parfois certains sacrifices, je vais y réfléchir. » avec les tags « réfléchi« , »curieux«
Voici le résultat de la comptabilisation de chaque tag, et donc soft-skill en fonction de la proposition qui a été choisie par l’utilisateur:
Résultat
casanier
instinctif
audacieux
curieux
réfléchi
P1
100%
100%
0%
0%
0%
P2
0%
100%
100%
100%
0%
P3
0%
0%
0%
100%
100%
Illustration avec le soft-skill à choix multiple
On reprend le même exemple que ci-dessus mais en considérant maintenant que la question est à choix multiple.
Résultat
casanier
instinctif
audacieux
curieux
réfléchi
P1
100%
50%
0%
0%
0%
Pourquoi 50% pour le soft-skill « Instinctif » ? Parce qu’il n’a été sélectionné qu’une seule fois sur deux possibles : P1 et P2
Résultat
casanier
instinctif
audacieux
curieux
réfléchi
P1 et P2
100%
100%
100%
50%
0%
Ici, l’utilisateur totalise 100% pour le soft-skill « Instinctif » car toutes les propositions de réponses qui y faisaient référence (P1 et P2) ont été sélectionnées et totalise 50% pour le soft skill « curieux » car il n’a été sélectionné qu’une seule fois sur deux possibles (P2 et P3).
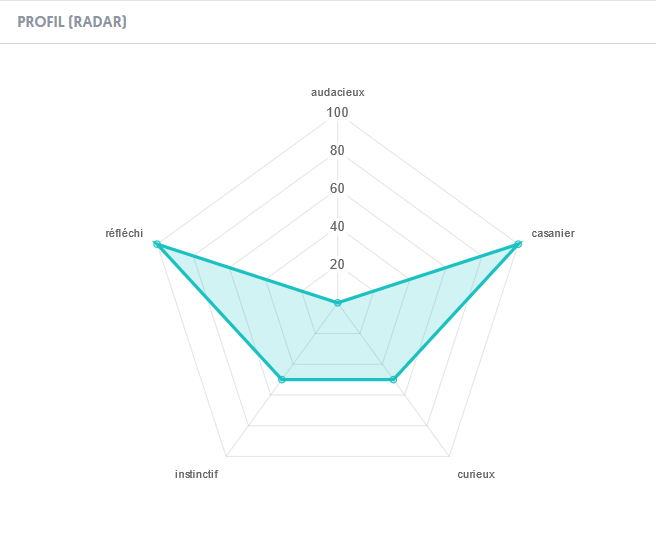
À la fin d’un test qui inclut des questions soft skills, une analyse en forme de graphe radar est présentée à l’utilisateur, si l’option correspondante a été cochée parmi les réglages du questionnaire.
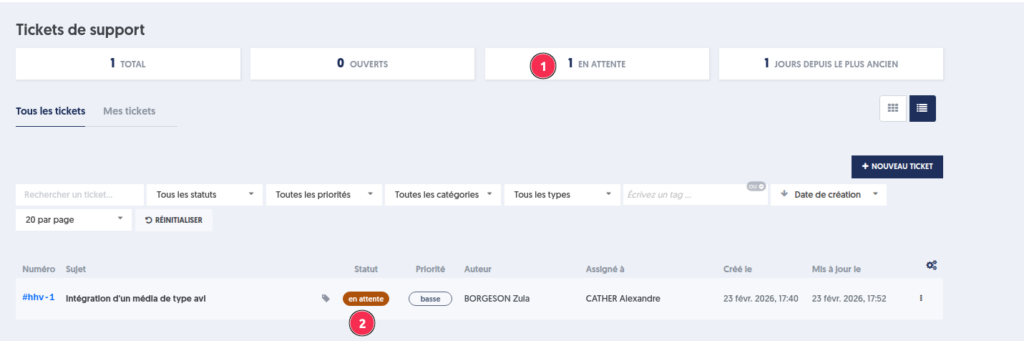
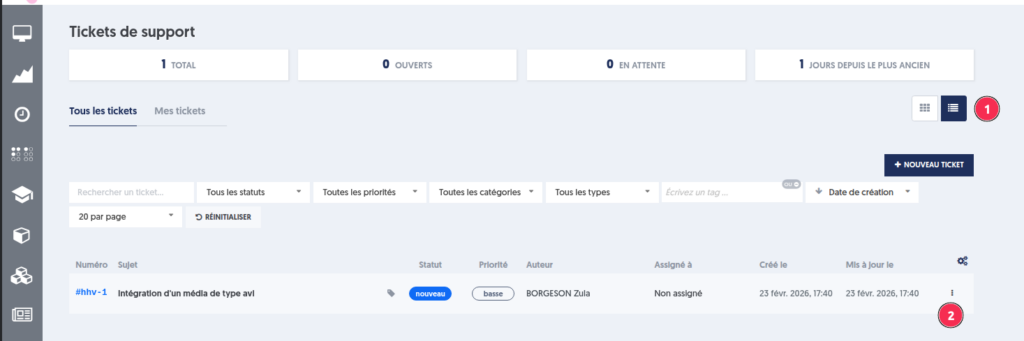
La prise en charge d’un ticket se matérialise par un changement de statut (1), qui passe de » Nouveau » à » Ouvert « .
Le ticket est ensuite assigné à un membre de l’équipe de maintenance, responsable de son traitement (2).
La date de mise à jour (3) permet de suivre la dernière action effectuée sur le ticket et d’identifier la date de son dernier traitement.
Commentaire
Les tickets peuvent nécessiter un complément d’information pour être traité. Dans ce cas, l’équipe de maintenance rédige un commentaire de demande et passe le ticket » en attente « .
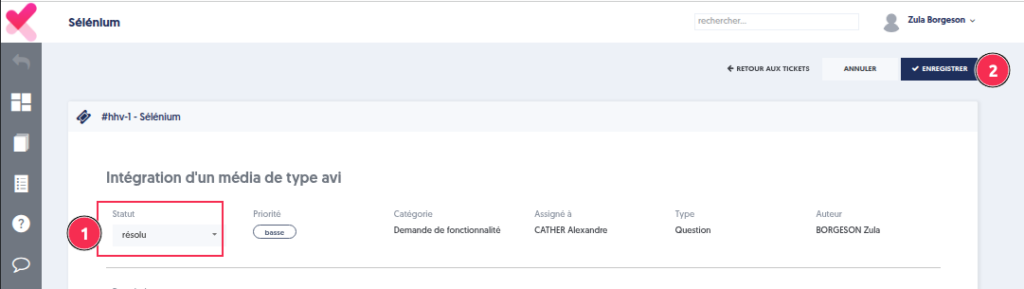
Modification du statut
Il est possible de modifier le statut du ticket. Par exemple, un ticket peut passer au statut résolu quand il a été corrigé.
Notification
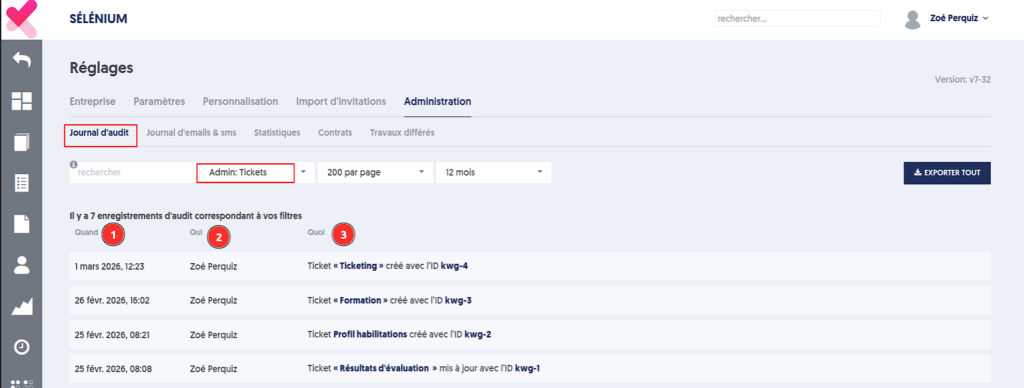
Toutes les actions effectuées sur les tickets sont enregistrées dans le journal d’audit.
En filtrant sur le type d’événement « Admin : Tickets « , ainsi que sur la période souhaitée, vous pouvez effectuer une recherche précise des activités liées au ticketing.
Chaque ligne indique :
la date et l’heure de l’action,
son auteur
le détail de l’événement (création, mise à jour, commentaire, etc.) avec son numéro
Notification par email
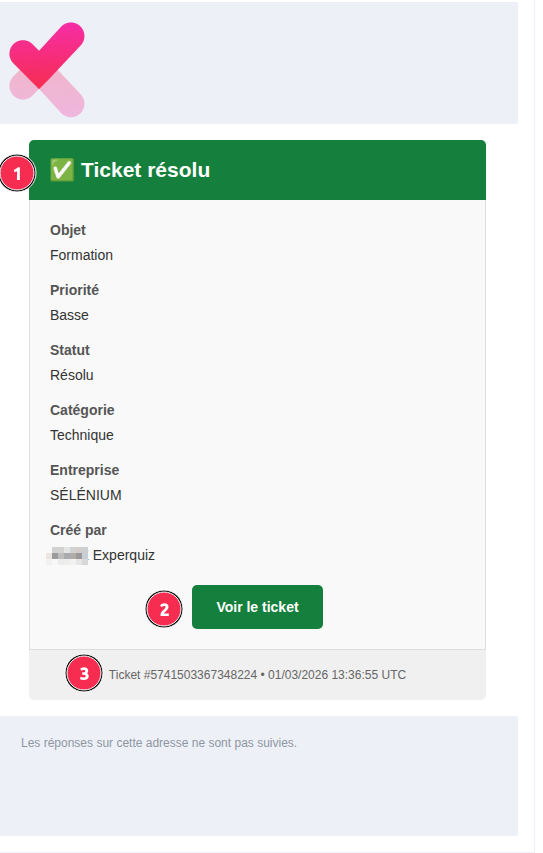
À chaque modification du statut d’un ticket (prise en charge, mise en attente, résolution, clôture…), son auteur reçoit une notification par email.
L’en-tête du message synthétise l’action effectuée sur le ticket.
Un bouton » Voir le ticket » permet d’accéder directement à celui-ci.
En pied de message, un récapitulatif mentionne l’identifiant du ticket ainsi que la date et l’heure de l’action.
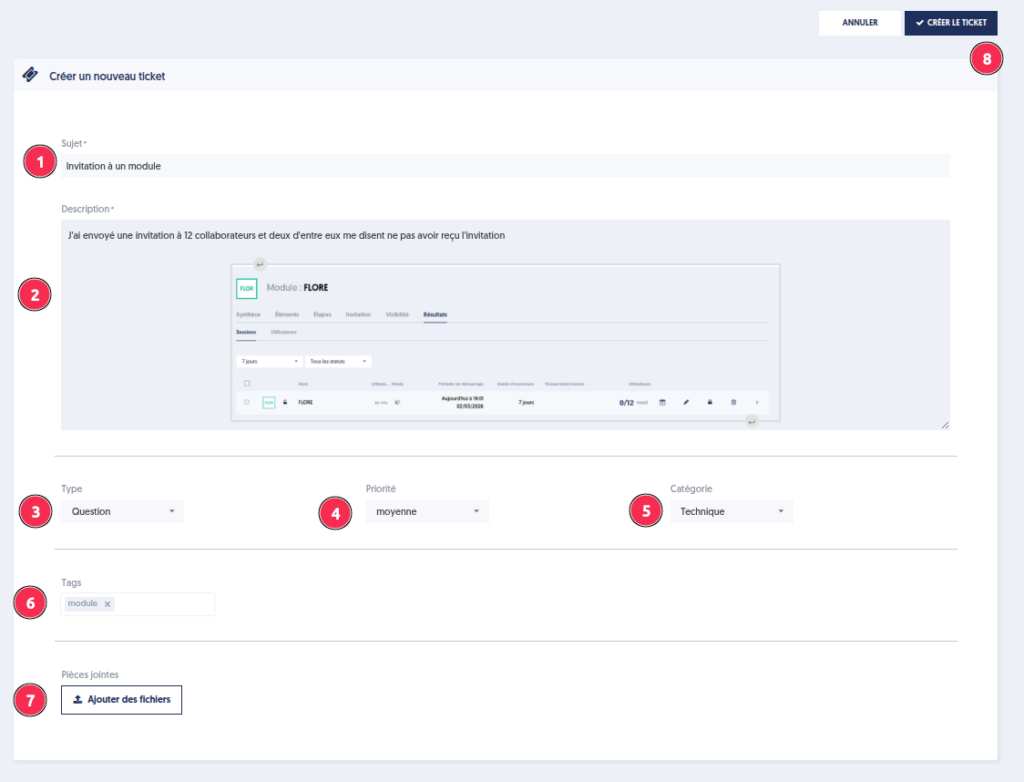
Pour créer un nouveau ticket, cliquez sur le bouton » Créer un ticket « , puis renseignez les éléments suivants :
Le sujet : un titre clair et synthétique de votre demande
La description détaillée : décrivez précisément le contexte et le problème rencontré, en ajoutant si possible une copie d’écran
Le type : question, anomalie, demande d’évolution, …
La priorité : indique le niveau d’urgence de traitement
Les tags : mots-clés internes permettant d’affiner la recherche et le suivi de vos tickets
Les pièces jointes : elles facilitent la prise en charge du ticket. Par exemple, en cas de problème d’export ou d’import, joindre le fichier concerné est particulièrement utile.
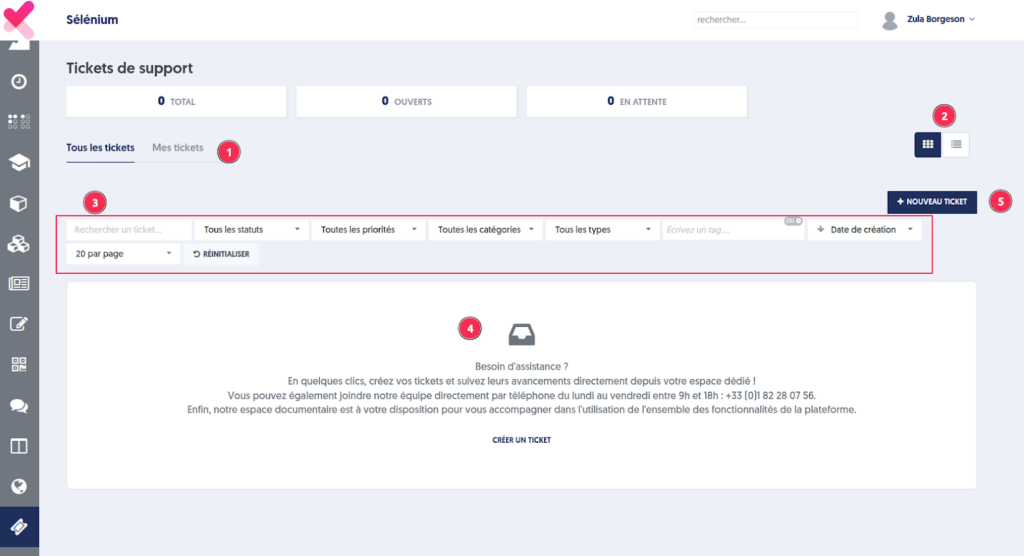
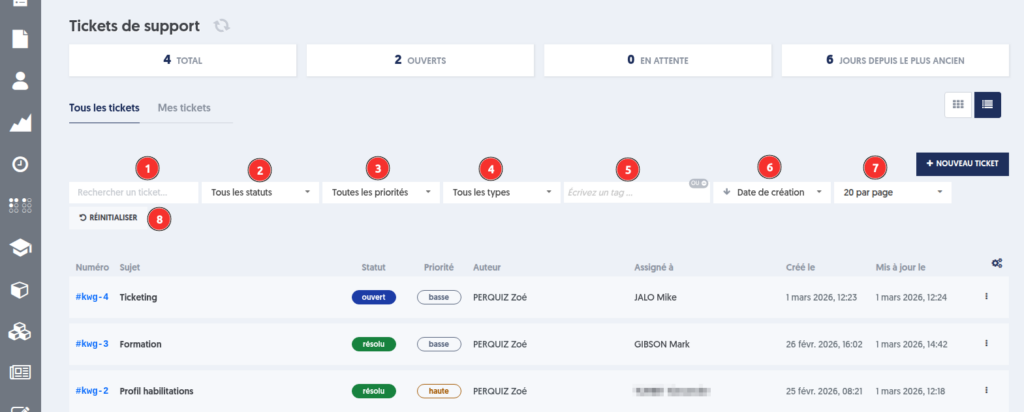
En cliquant sur l’option » Tickets » sur le menu principal, vous parvenez à la page de vos tickets. Vous ne voyez que les tickets de votre entreprise.
La page comprend :
Les onglets » Tous les tickets » et » Mes tickets «
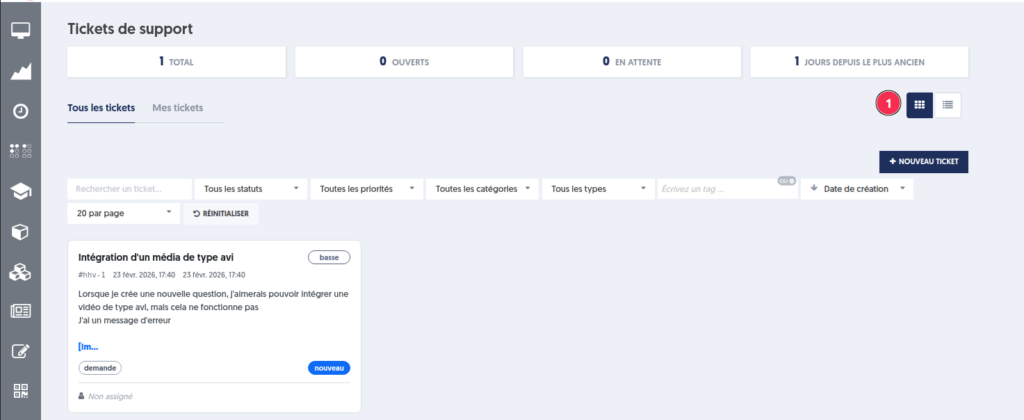
Un affichage au choix sous forme de cartes ou de liste
Des filtres de recherche (statut, priorité, catégorie, type, etc.) pour affiner les résultats
Un message d’assistance en l’absence de ticket
Un accès direct à la création d’un nouveau ticket
Filtres de tickets
La page Tickets propose plusieurs filtres permettant d’affiner l’affichage des demandes.
La recherche textuelle Une recherche par mot-clé permet de retrouver un ticket à partir d’une chaîne de caractères présente dans son titre ou sa description.
Filtre par statut du ticket Cinq statuts sont disponibles :
Nouveau : le ticket vient d’être créé et transmis
Ouvert : le ticket a été pris en compte
En attente : le ticket nécessite des informations complémentaires
Résolu : le ticket est traité et peut être testé par son propriétaire
Fermé : le ticket est clôturé
Filtre par priorité Quatre niveaux de priorité sont disponibles :
Basse
Moyenne
Haute
Urgente
La priorité indique le niveau d’urgence et la vitesse de prise en charge attendue. Elle est définie lors de la création du ticket, mais peut être réévaluée par l’équipe de maintenance Experquiz si nécessaire.
Filtre par type Les types sont :
Question
Problème
Filtre par tag Vous pouvez ajouter des mots-clés personnalisés pour qualifier vos tickets et ce filtre permet d’affiner la recherche sur ce critère.
Tri par date de création ou date de mise à jour
Nombre de tickets affichés par page
Bouton Réinitialiser pour effacer l’ensemble des filtres actifs
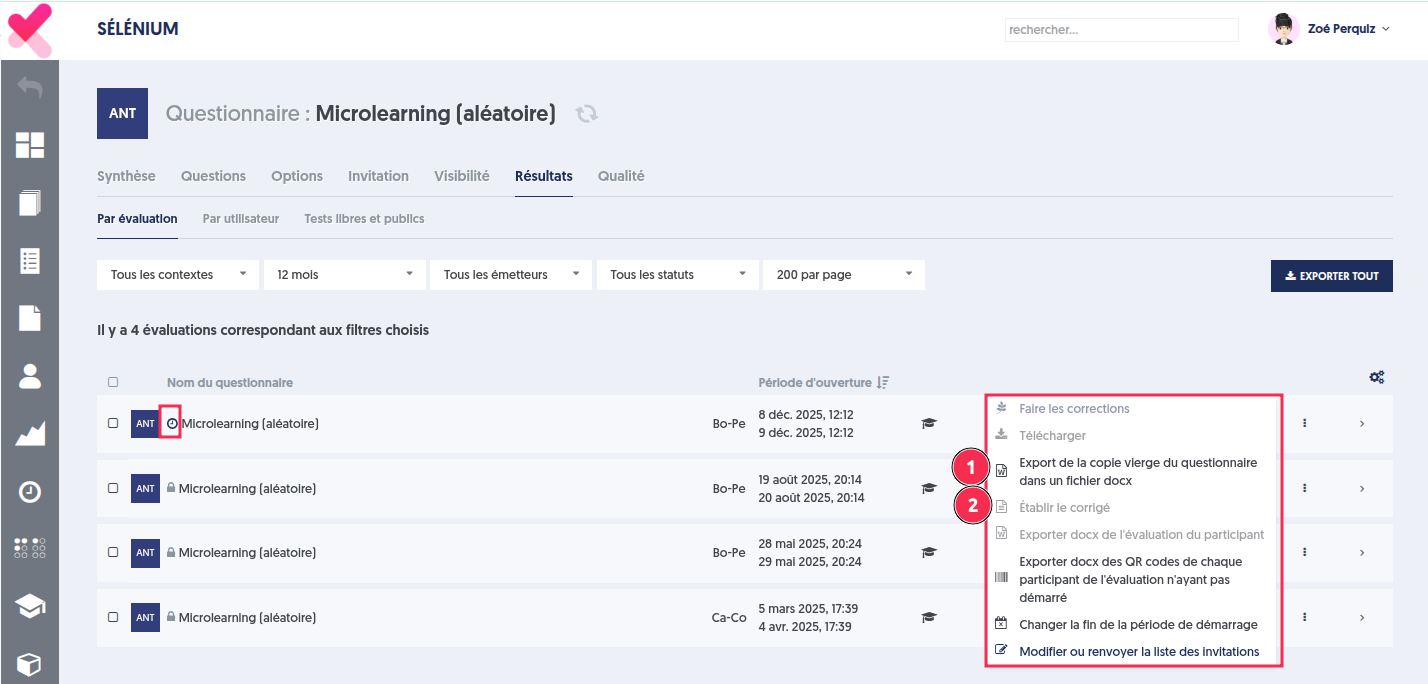
Deux actions de gestion sont possibles au niveau de l’évaluation :
Export de la copie vierge du questionnaire dans un fichier docx.
Établir le corrigé de l’évaluation.
Elles permettent ainsi :
d’accéder immédiatement à une version vierge du questionnaire qui peut être accessible avant le démarrage de l’évaluation.
Et, après l’invitation, d’obtenir le corrigé exact, correspondant au tirage réel des questions présenté au participant.
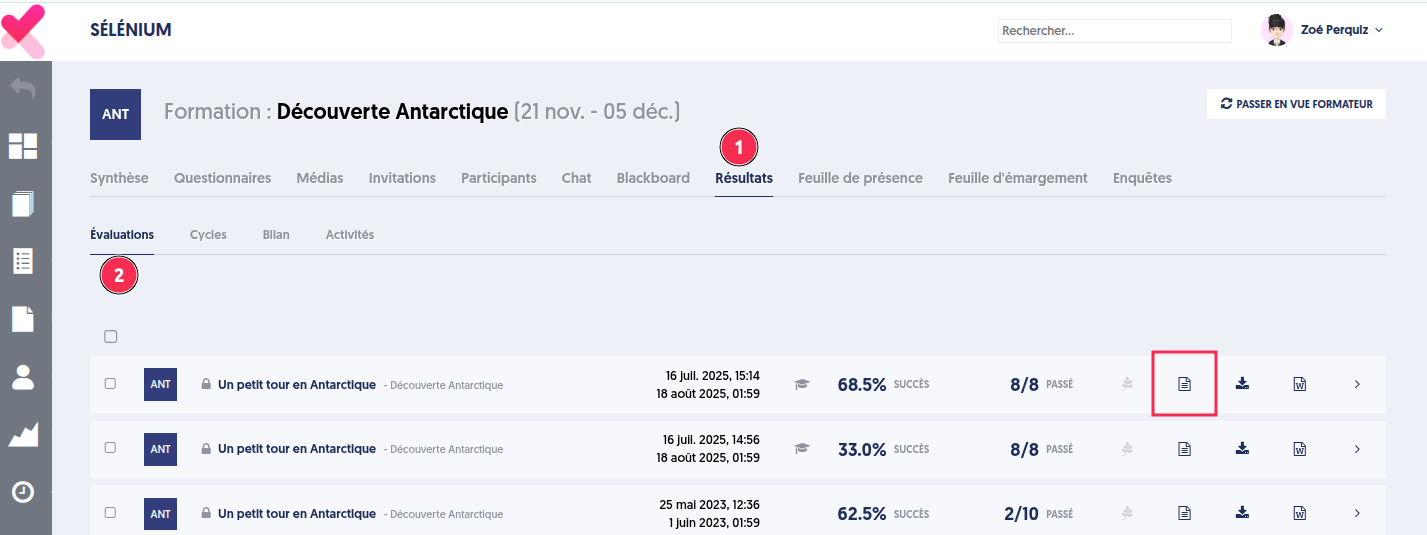
Menu Formation
Dans le menu formation, les résultats des évaluations passées durant la session de formation sont accessibles dans l’onglet “Résultats”, sous-onglet “Évaluations”.
La fonctionnalité d’export du questionnaire corrigé a été également ajoutée sur cette page.
Une évaluation correspond à une invitation à passer un questionnaire, adressée à plusieurs personnes. Lorsqu’une évaluation est terminée, une synthèse des résultats est présentée : statistiques sur les réponses des participants, temps de réponse, erreurs les plus fréquentes, …
La page regroupant l’ensemble des évaluations est accessible via le menu “Résultats/Évaluations”.
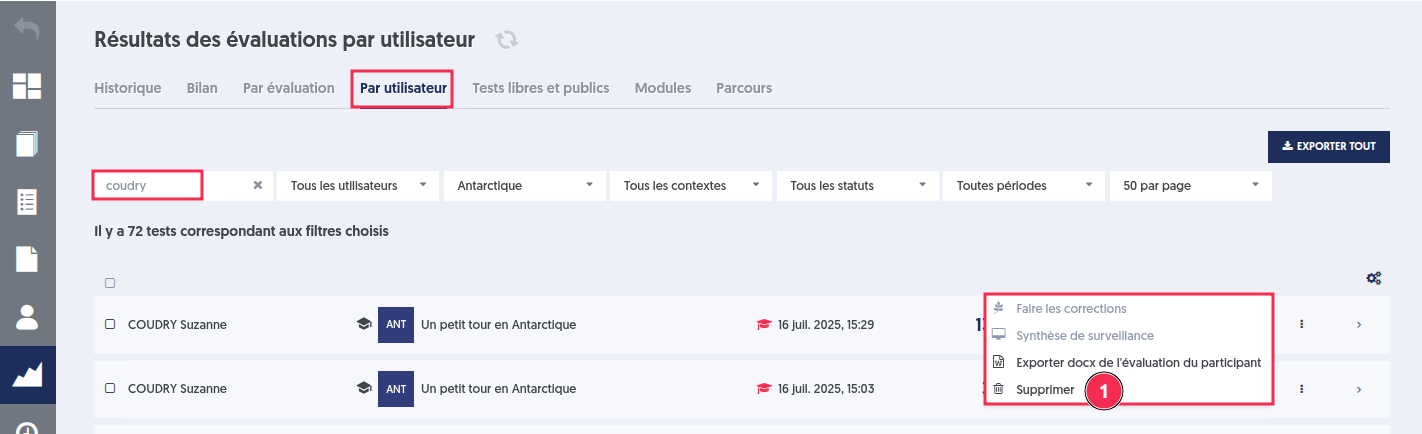
Les tests individuels de chaque participant sont quant à eux consultables dans le menu “Résultats/Par utilisateur”.
La suppression d’un test individuel inclus dans une évaluation se réalise depuis la page “Résultats/Par utilisateur”.
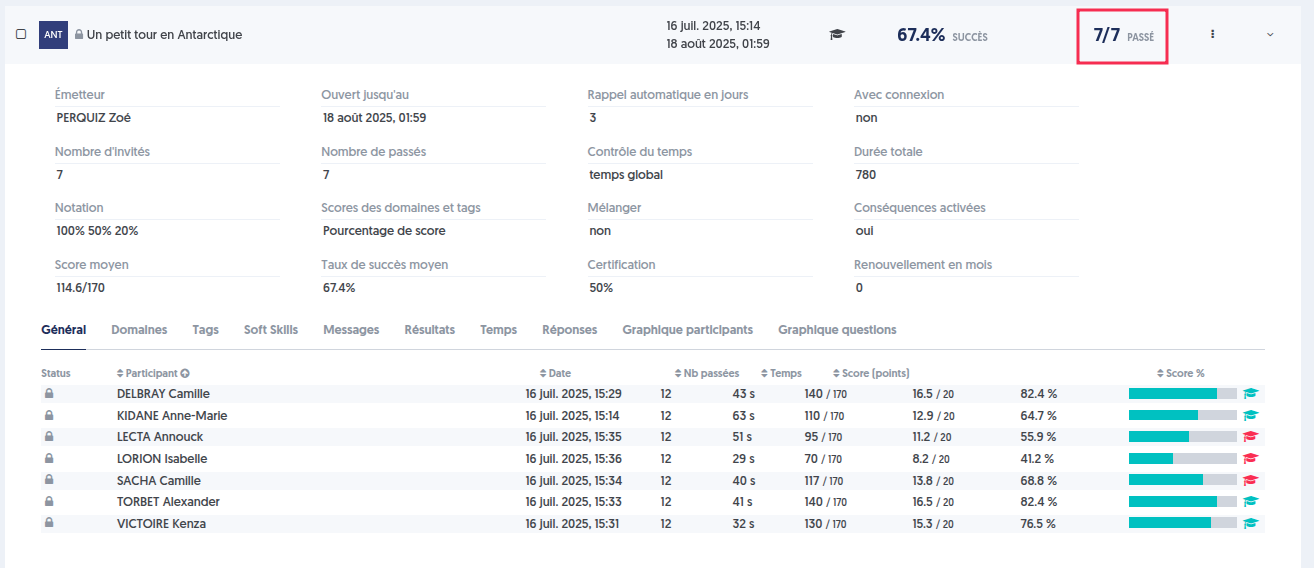
Par exemple, prenons l’évaluation sur le questionnaire “Un petit tour en Antarctique” passée par 8 utilisateurs et supprimons le test de Suzanne Coudry.
Supprimons le test dans la page “Résultats/Par utilisateur”.
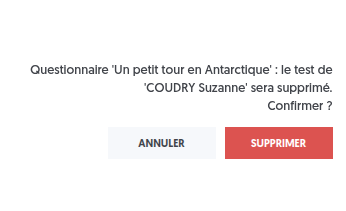
Une demande de confirmation apparaît alors afin de valider la suppression.
L’évaluation a été mise à jour.
Cette possibilité n’est pas disponible pour les évaluations de module ou de parcours.
En effet, un module est constitué d’une suite d’étapes, et une évaluation peut valider une étape permettant d’accéder aux suivantes. Supprimer un test déjà validé perturberait fortement le déroulement du module.
Experquiz propose de multiples analyses des scores, sur différents axes et avec de nombreuses possibilités de filtres.
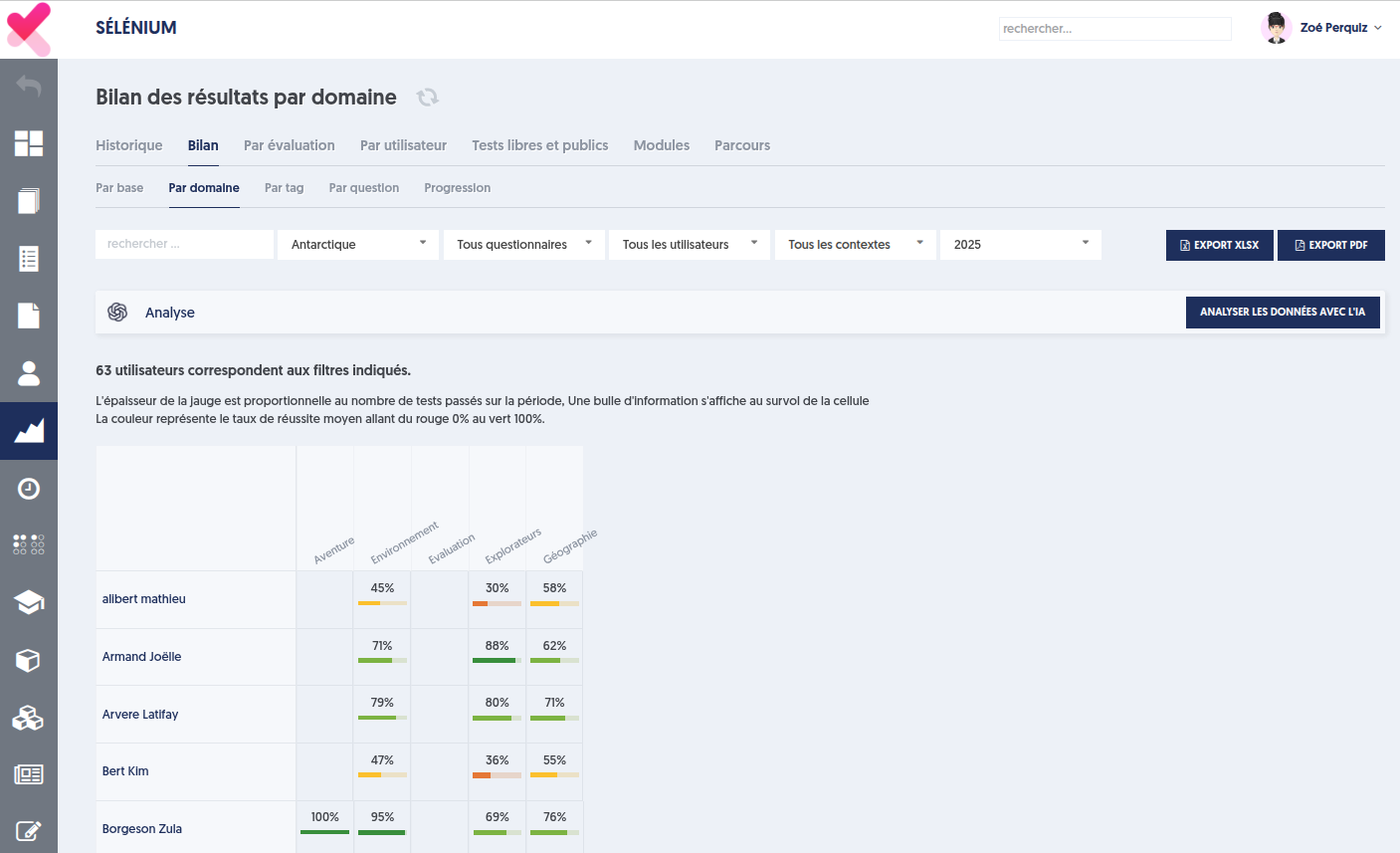
Ces analyses sont disponibles sur l’onglet “Bilans” de la page “Résultats”, comme illustré ci-dessous :
Vous disposez de 5 sous-onglets : par base, par domaine, par tag, par question, et progression.
Nous nous intéressons ici aux 3 onglets du milieu : par domaine, par tag et par question.
Le premier onglet vous apporte une analyse des scores par domaine obtenus par chaque utilisateur. Vous pouvez filtrer :
Une base spécifique
Un questionnaire spécifique, ou bien tous les questionnaires
Un groupe d’utilisateurs ou bien tous les utilisateurs
Un contexte de passage spécifique : évaluation, certification, test libre
Et enfin une période sur laquelle les passages de tests sont considérés.
Une fois tous les filtres réglés selon vos besoins, l’onglet “par domaine” présente, pour chaque personne incluse dans le périmètre, le score obtenu sur chacun des domaines. C’est-à-dire la moyenne des scores obtenus sur toutes les questions qui appartiennent à ce domaine. Notez que si la personne a effectué plusieurs tests sur la période, les valeurs affichées correspondent à la moyenne sur l’ensemble des tests.
D’une manière très semblable, les onglets suivants, “par tag” et “par question”, présentent les résultats consolidés de chaque utilisateur, pour chaque tag et pour chaque question.
Notez que si l’utilisateur qui est connecté et qui consulte ces analyses n’a accès qu’à un périmètre réduit d’utilisateur (que ce soit via la notion de groupe ou bien via l’organigramme de l’entreprise), alors ces pages sont naturellement filtrées sur le périmètre autorisé.
Par ailleurs, ces pages offrent la possibilité d’analyses réalisées par l’Intelligence Artificielle. Mais c’est un autre sujet !
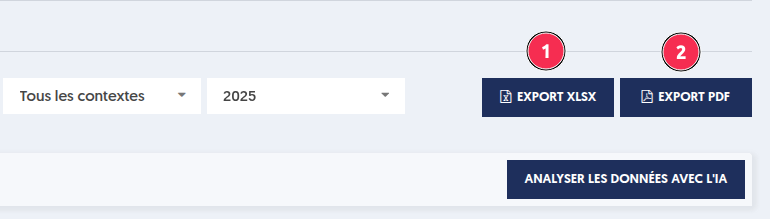
La fonctionnalité nouvelle permet d’exporter ces analyses, soit dans un fichier Pdf, soit dans un fichier Excel.
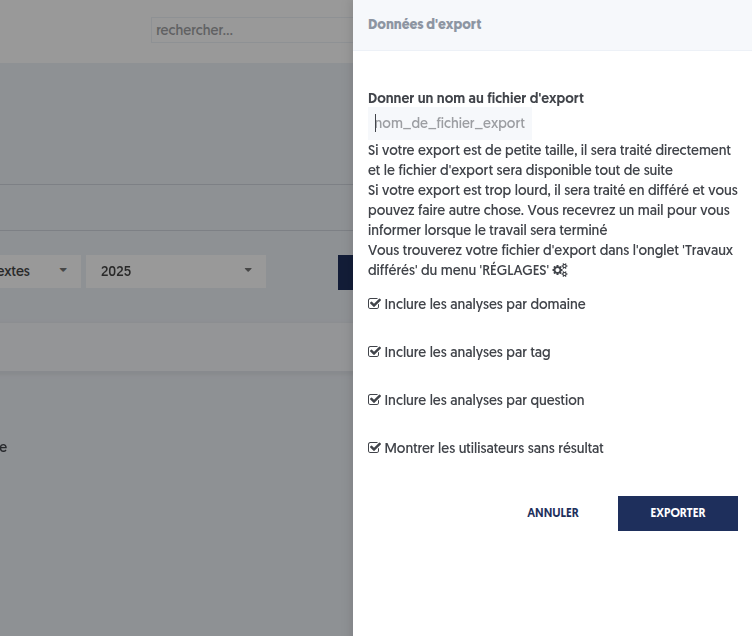
Lorsque vous cliquez l’un des boutons, un panneau s’ouvre sur la droite, vous permettant d’ajuster le contenu de votre fichier :
Inclure ou non les analyses par domaine, par tag et par question.
Inclure la totalité des utilisateurs ou bien uniquement les utilisateurs pour lesquels il existe des résultats.
Comme pour tous les exports de fichiers qui peuvent être importants, il y a deux possibilités, en fonction du volume de données :
Si vos données incluent moins de 200 utilisateurs, l’export sera synchrone, c’est-à-dire que vous pourrez attendre que le fichier soit créé, et il sera affiché immédiatement.
Si vos données sont plus volumineuses, l’export sera différé, c’est-à-dire qu’il sera réalisé pendant que vous pouvez continuer à travailler. Lorsque le fichier sera prêt, vous recevrez un email d’information.
Dans un cas comme dans l’autre, vous pouvez obtenir le fichier sur la page “Réglages”, onglet “Administration”, sous-onglet “Travaux différés”.
Analyses de la qualité des questions et fiabilité des tests
Chaque fois qu’une personne répond à une question, on obtient de l’information quant à la connaissance de la personne (et c’est en général ce qui nous intéresse le plus), mais on obtient aussi de l’information relativement à la question elle-même. Par exemple, est-ce une question facile (réussie par beaucoup de participants) ou bien difficile (réussie par peu de participants) ?
Mais il y a beaucoup d’autres analyses possibles, et très importantes.
Parlons de la corrélation. D’une manière générale, si l’on a une base de questions portant sur un sujet particulier, disons par exemple le RGPD, on s’attend à ce que “plus une personne connaît bien le RGPD, plus il répond correctement à chacune des questions”. Cela semble très simple et presque évident. Si je considère une question spécifique de ma base, disons la question #23, je m’attends à ce que “plus une personne a un bon score global, plus elle réussit aussi la question #23. Ce n’est pas systématique : il est possible qu’une personne d’un excellent niveau ait échoué à cette question. Mais c’est vrai en général, c’est-à-dire que la probabilité de succès à la question #23 est corrélée à la probabilité de succès au test global.
Si l’on dispose de suffisamment de données, cette corrélation peut se mesurer mathématiquement, et l’on pourra alors se demander, pour chacune des questions, si elle est bien corrélée à la base dans son ensemble. Cette corrélation est une bonne mesure de la qualité de la question, c’est-à-dire de la capacité de cette question de contribuer à la mesure de la connaissance sur cette thématique.
À partir de ce type d’analyse, il est possible de calculer le coefficient “Alpha de Cronbach”, qui est une généralisation du coefficient de Kuder-Richardson, appelé KR-20. On peut dire schématiquement que c’est une mesure d’ensemble de la qualité de la base de questions, autrement dit : plus ce coefficient est élevé, plus les tests utilisant ces questions pourront être fiables. En général, on vise un KR20 supérieur à 70%, et il est courant de parvenir à des valeurs supérieures à 90%.
Une valeur de KR20 inférieure à 70% n’est pas satisfaisante, c’est-à-dire que vos tests ne seront pas d’une fiabilité suffisante. Que peut-on y faire ? C’est assez facile en fait : il suffit de rechercher les questions qui ont une faible corrélation, et soit de les améliorer, soit encore plus simplement de les supprimer.
Les questions qui ont une corrélation négative avec la base dans son ensemble sont vraiment à corriger ou supprimer : ce sont des questions telles que “plus une personne maîtrise bien la connaissance sur cette thématique, moins elle trouve la bonne réponse à cette question”. Autant dire que la question est sans doute soit très mal formulée, soit tout simplement erronée (la bonne réponse n’est pas celle indiquée, les experts connaissent la bonne réponse, donc ils échouent).
À partir de la valeur du KR20, il est possible de déterminer l’erreur standard, c’est-à-dire la marge d’erreur associée aux résultats obtenus à un test utilisant ces questions.
Même avec d’excellentes questions, il est courant que l’erreur standard soit de l’ordre de 5 %, soit environ ±1 point sur une note de 20. Cet indicateur est essentiel : si votre erreur standard est de 15 %, par exemple, un score de 15/20 doit en réalité être interprété comme se situant entre 12/20 et 18/20. Le niveau d’imprécision devient alors préoccupant.
Notons que l’erreur standard dépend à la fois du KR20 et du nombre de questions du test. Plus le test comporte de questions, plus l’erreur standard diminue. C’est pourquoi cet indicateur est surtout pertinent au niveau d’un questionnaire donné, et non à l’échelle d’une base complète de questions.
Retenez surtout ceci : les analyses statistiques de qualité font intervenir des calculs un peu complexes, mais vous n’avez pas à vous en préoccuper, il vous suffit de regarder les résultats et les recommandations qui vous sont présentés.
Ces analyses sont offertes par la plateforme Experquiz depuis des années, mais elles ont été sensiblement améliorées, et rendues plus performantes, dans cette version.
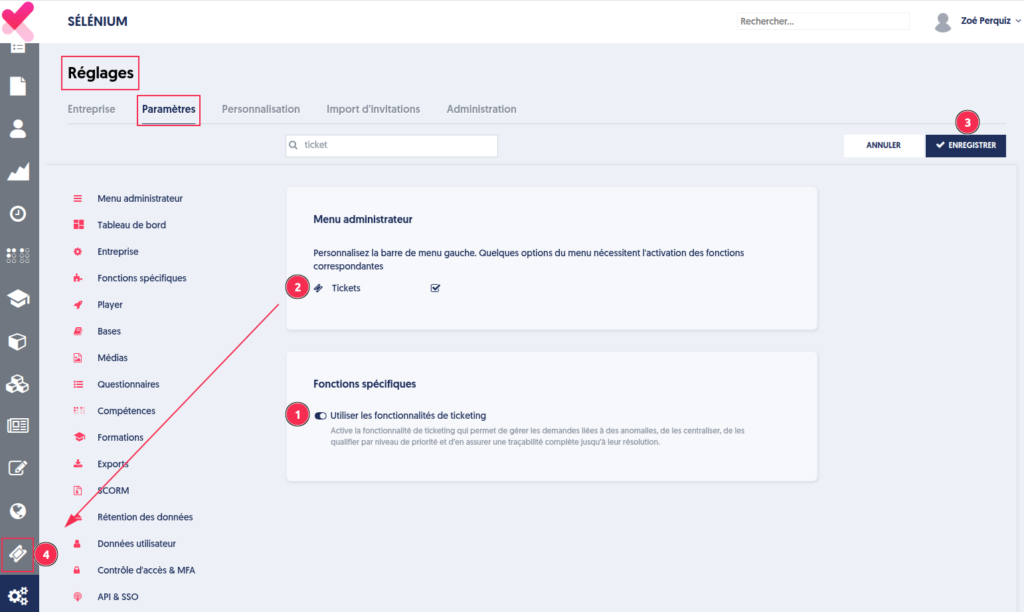
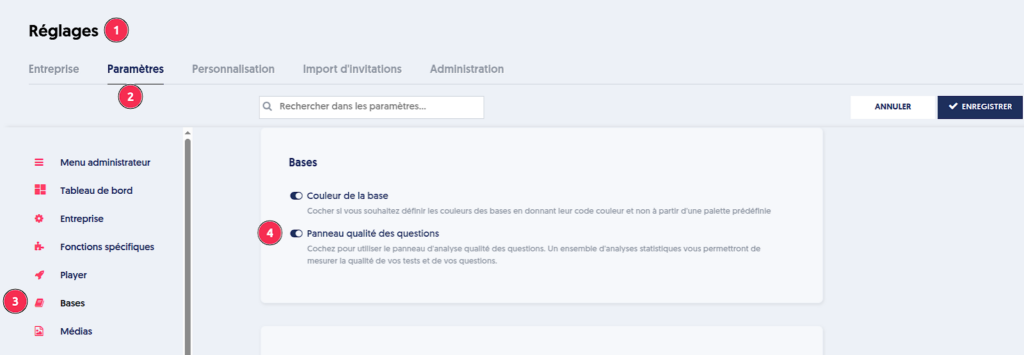
Pour accéder aux analyses qualité, il vous faut en premier lieu activer la fonctionnalité dans les réglages de votre entreprise (Onglet “Paramètres”, section “Bases”).
Au niveau de chacune de vos bases de questions, vous disposez alors d’un onglet “Qualité”, qui se présente comme ceci:
Vous disposez des filtres suivants :
Soit tous les questionnaires, soit l’un seulement des questionnaires de la base.
Vous pouvez choisir un contexte de test particulier, par exemple si vous pensez que les résultats relevant d’une évaluation sont plus pertinents que les résultats en tests libres.
Vous pouvez sélectionner une période spécifique, pour ne considérer que les résultats de cet intervalle.
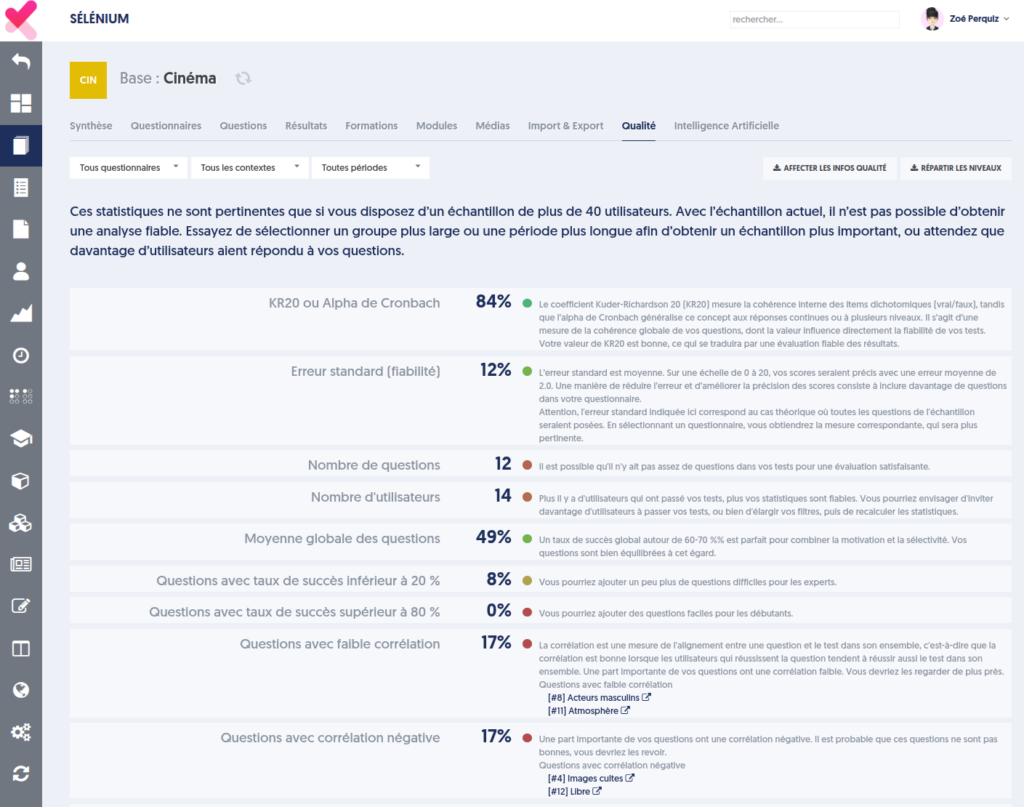
La page présente ensuite un tableau d’indicateurs, et pour chacun des indicateurs, une pastille de couleur indiquant dans quelle mesure la valeur est statisfaisante, et un commentaire extensif accompagné de recommandations.
Si votre échantillon (les tests correspondant à vos filtres) porte sur moins de 40 utilisateurs, un avertissement est présenté en haut de page, vous mettant en garde sur la fiabilité des analyses. Ce type d’analyse n’est vraiment pertinent que si plus de 40 utilisateurs ont répondu à vos questions.
Les indicateurs sont les suivants :
Alpha de Cronbach / KR20 : voir l’explication au chapitre précédent.
Erreur standard : Voir l’explication au chapitre précédent. Rappelons qu’elle n’a vraiment de sens que pour un questionnaire donné.
Nombre de questions : pour des scores fiables, il faut que vos tests incluent un nombre suffisant de questions, si possible au moins 30 questions. Sur des tests de moins de 20 questions, les aléas sont plus importants, et l’erreur standard sera plus importante.
Nombre d’utilisateurs : comme énoncé en préambule, ces analyses requièrent au moins 40 utilisateurs.
Moyenne globale des questions : on considère qu’un taux de succès moyen autour de 60 à 70% est idéal pour combiner motivation (le participant est motivé par ses succès) et sélectivité (tous les participants ne réussissent pas toutes les questions). Mais cet indicateur n’a pas une importance critique.
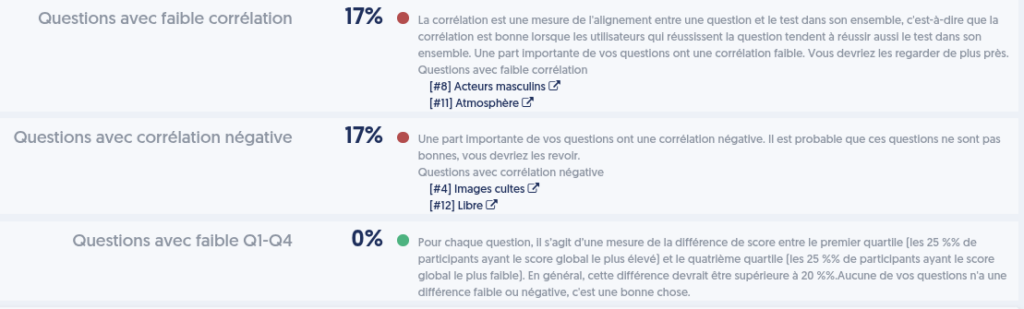
Questions avec taux de succès inférieur à 20 %
Questions avec taux de succès supérieur à 80 %
Questions avec faible corrélation : voir plus haut, l’explication relative à la notion de corrélation. Une question de faible corrélation est une question telle que “les participants les plus experts ne répondent pas mieux à cette question que les participants les plus faibles”. La question n’est peut-être pas erronée, mais elle ne semble pas mesurer la même connaissance que les autres questions.
Questions avec corrélation négative : comme vu plus haut, les questions à corrélation négative sont vraiment un souci, il faut absolument s’en préoccuper car elles dégradent la qualité de vos tests.
Questions avec faible Q1-Q4 : on fait appel ici à une notion qui ressemble à la corrélation, mais se calcule d’une manière un peu différente.
Pour ces trois derniers indicateurs, le tableau présente la liste complète des questions concernées, avec un lien permettant de modifier la question dans un nouvel onglet.
Les graphiques
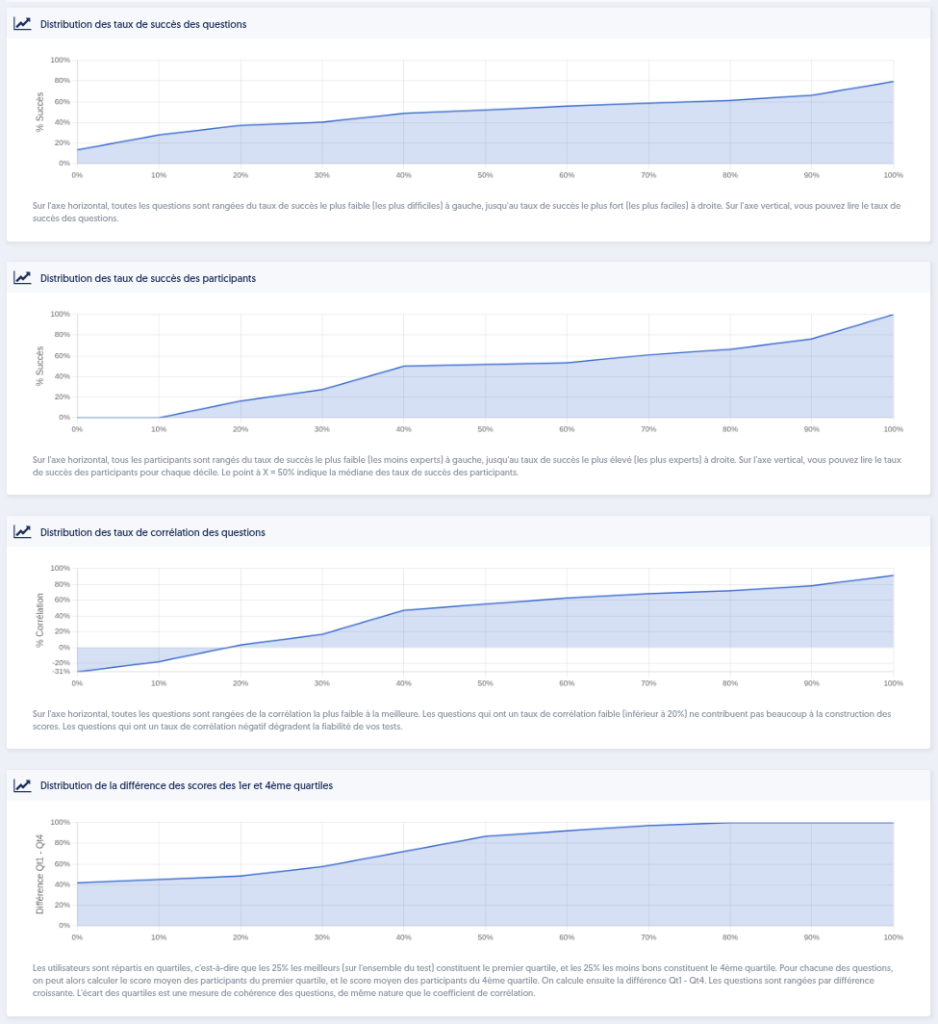
La partie suivante de la page présente 4 graphiques :
La distribution du taux de succès des questions : sur l’axe horizontal, toutes les questions sont rangées du taux de succès le plus faible (les plus difficiles) à gauche, jusqu’au taux de succès le plus fort (les plus faciles) à droite. Sur l’axe vertical, vous pouvez lire le taux de succès des questions. Idéalement, c’est une courbe qui pourrait être une droite conduisant de 0% à gauche jusqu’à 100% à droite. Il n’y a pas véritablement de mauvaise configuration, mais si par exemple la courbe atteint les 100% dès le milieu, c’est-à-dire que la moitié de vos questions ont un taux de succès de 100%, cela signifie sans doutes qu’il manque des questions plus difficiles, car toutes ces questions que tout le monde réussit n’apporte pas tellement à vos scores.
La distribution des taux de succès des participants : sur l’axe horizontal, tous les participants sont rangés du taux de succès le plus faible (les moins experts) à gauche, jusqu’au taux de succès le plus élevé (les plus experts) à droite. Sur l’axe vertical, vous pouvez lire le taux de succès des participants pour chaque décile. Le point à X = 50% indique la médiane des taux de succès des participants.
La distribution des taux de corrélation des questions : sur l’axe horizontal, toutes les questions sont rangées de la corrélation la plus faible à la meilleure. Les questions qui ont un taux de corrélation faible (inférieur à 20%) ne contribuent pas beaucoup à la construction des scores. Les questions qui ont un taux de corrélation négatif dégradent la fiabilité de vos tests. Sur l’image ci-dessous, on voit que quelques questions ont une corrélation négative.
La distribution de la différence des scores des 1er et 4ème quartiles : les utilisateurs sont répartis en quartiles, c’est-à-dire que les 25% les meilleurs (sur l’ensemble du test) constituent le premier quartile, et les 25% les moins bons constituent le 4ème quartile. Pour chacune des questions, on peut alors calculer le score moyen des participants du premier quartile, et le score moyen des participants du 4ème quartile. On calcule ensuite la différence Qt1 – Qt4. Les questions sont rangées par différence croissante. L’écart des quartiles est une mesure de cohérence des questions, de même nature que le coefficient de corrélation.
La matrice de corrélation et les clusters de questions
En bas de la page, vous trouverez la matrice de corrélation complète, qui présente, sous la forme de petits carrés colorés, la corrélation entre chaque couple de questions de la base.
Les cases de couleur verte, plus ou moins intense, représentent un couple de questions qui ont une corrélation positive. Cela signifie que si les personnes réussissent la première question, il est probable qu‘ils réussissent également la seconde. Plus la couleur verte est intense, plus la corrélation est forte.
Réciproquement, les cases de couleur rouge représentent un couple de question qui ont une corrélation négative : lorsque l’on réussit à la première question, alors il est probable que l’on échoue à la seconde.
Sur la base de ces corrélations, on peut construire ensuite des groupes de questions qui sont corrélées entre elles, des clusters. Lorsqu’une personne réussit l’une des questions du clusters, il est probable (très probable ou un peu probable), qu’elle réussisse également les autres questions du cluster.
Cela ne doit pas amener à penser que les questions du cluster sont égales et que l’une seulement pourrait suffire. D’abord la corrélation ne prouve pas que la connaissance mesurée est la même, et de plus il est toujours bon d’aborder une notion sous différents angles, avec des questions variées.
Les boutons d’action
En haut de cette page qualité, vous disposez de deux boutons d’action. Ils ne sont actifs que si l’échantillon inclut suffisamment de participants pour permettre des analyses satisfaisantes.
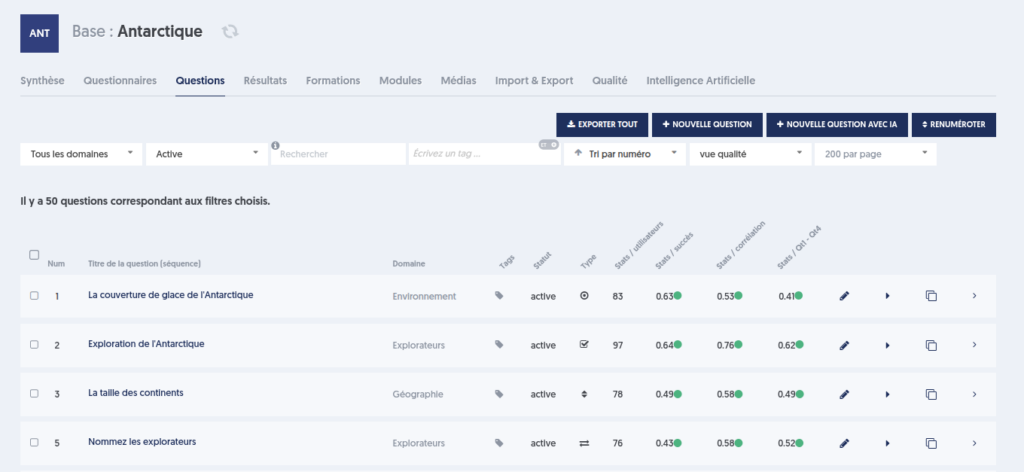
le bouton AFFECTER LES INFOS QUALITÉ : ce bouton attache les informations calculées ici à chacune des questions de la base. Ces informations peuvent ensuite être visualisées dans la liste des questions de la base, en choisissant la “vue qualité”. Ainsi vous disposerez, pour chaque question, de son taux de succès moyen, sa corrélation à l’ensemble de la base, l’écart des premiers et quatrième quartile.
le bouton RÉPARTIR LES NIVEAUX : ce bouton permet de redéfinir le niveau de difficulté de chacune des questions de la base. Les questions sont rangées de la plus facile (plus haut taux de succès) à la plus difficile (plus faible taux de succès), les 20% de questions les plus faciles reçoivent la valeur 1 pour leur niveau. Les 20% suivants auront la valeur 2. Et ainsi de suite jusqu’aux 20% les plus difficiles, qui auront la valeur 5.
C’est un outil très utile pour affecter un niveau de difficulté fiable. En effet, les contributeurs ne peuvent pas déterminer avec certitude si une question est de difficulté 2 ou bien 3. Avec cette fonctionnalité, vous avez une mesure de la difficulté basée sur les réponses de vos utilisateurs.
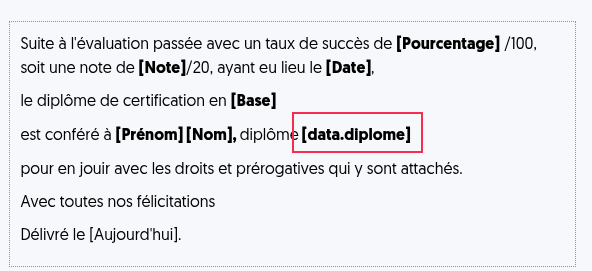
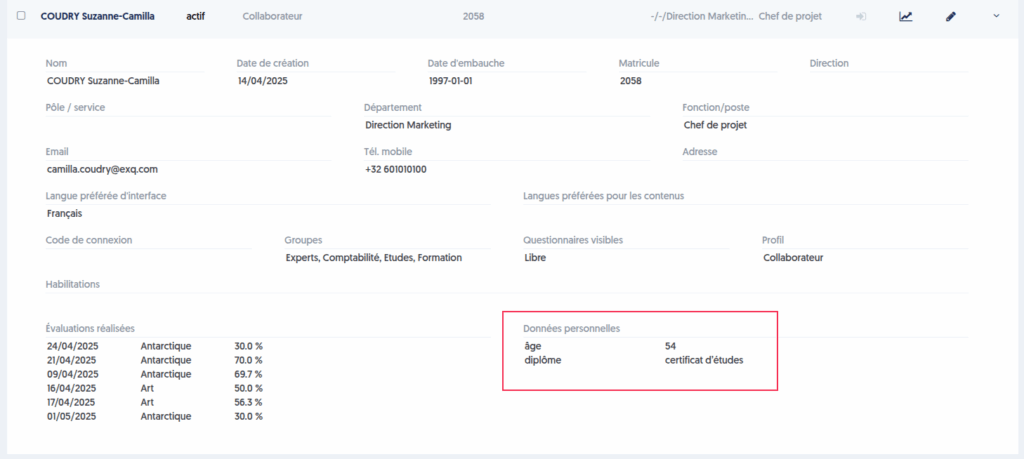
Experquiz permet d’importer des données personnelles spécifiques d’un utilisateur dans le fichier d’import (sous le format data:xxx).
Notez bien que l’on ne parle pas ici des données personnelles usuelles telles que nom, prénom, date de naissance, etc. Il s’agit d’attributs tout à fait spécifiques définis par l’entreprise.
Ces données peuvent être insérées comme variable dans la rédaction des diplômes en utilisant la syntaxe [data.xxx]
Vous pouvez les consulter dans le panneau de détails d’un utilisateur.