Experquiz propose deux types de questions qui permettent d’évaluer et mesurer les soft-skills. Ces questions ont la particularité de ne pas avoir de bonnes ou de mauvaises réponses :
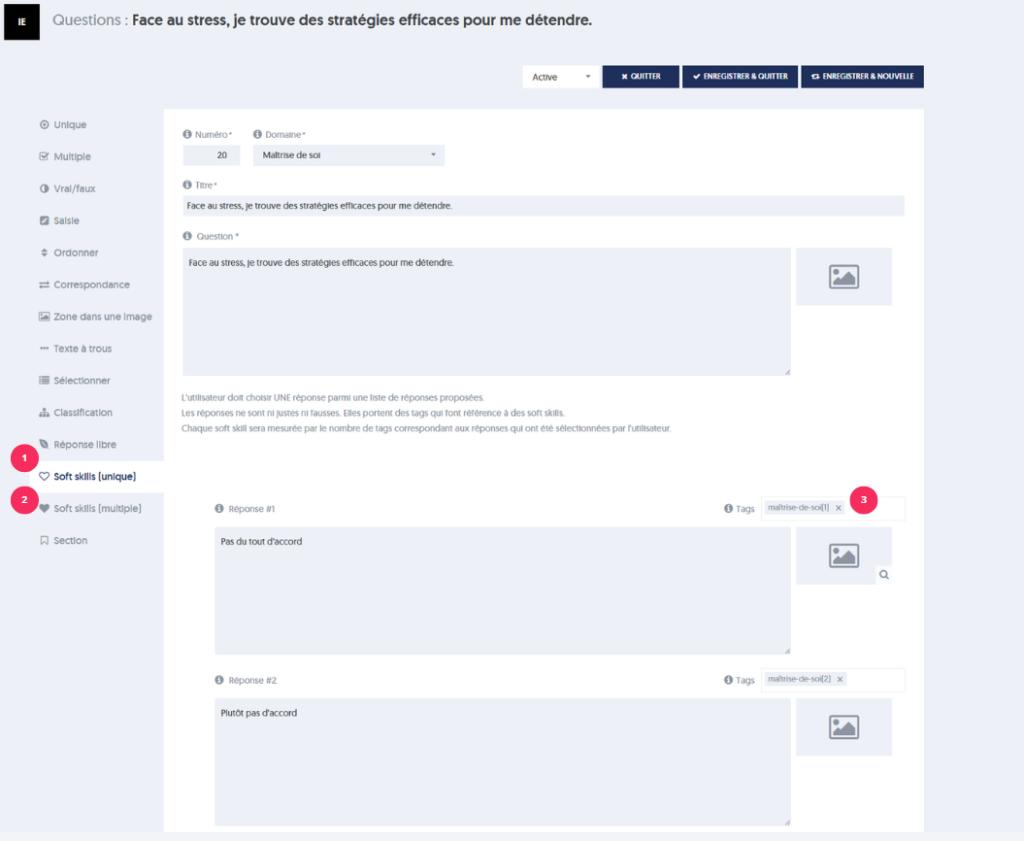
[1] Les soft-skills uniques : l’utilisateur doit choisir UNE réponse parmi une liste de réponses proposées.
[2] Les soft-skills multiples : l’utilisateur doit choisir PLUSIEURS réponses parmi une liste de réponses proposées.
[3] Chaque réponse est associée à un tag qui fait référence à des soft-skills.
Chaque compétence douce sera mesurée par le nombre de tags correspondant aux réponses qui ont été sélectionnées par l’utilisateur.
Pour en savoir plus sur la gestion des tags des questions de type « soft-skills », vous pouvez consulter notre page dédiée.
Comme pour les autres types de questions, il est possible de mélanger les réponses, d’ajouter une explication et une règle en cliquant sur le bouton « Plus de paramètres » :
Côté apprenant, l’affichage est le même que pour une question QCM classique. Un questionnaire peut comporter à la fois des questions classiques et des questions de type soft-skills..
Illustration avec le soft-skill à choix unique
À la question : « comment réagiriez-vous si l’on vous proposait d’accompagner une équipe scientifique pendant 3 mois dans l’Antarctique ?« , nous avons adjoints les propositions de réponses suivantes avec les tags qui les accompagnent :
P1 : « 3 mois avec une dizaine d »‘inconnus, dans la nuit et à -80°C, jamais ! » avec les tags « casanier« , »instinctif«
P2 : « Génial, une aventure qui va me sortir de mes habitudes, quand part-on ? » avec les tags « instinctif« , « audacieux« , »curieux«
P3 : « Pourquoi pas? Apprendre demande parfois certains sacrifices, je vais y réfléchir. » avec les tags « réfléchi« , »curieux«
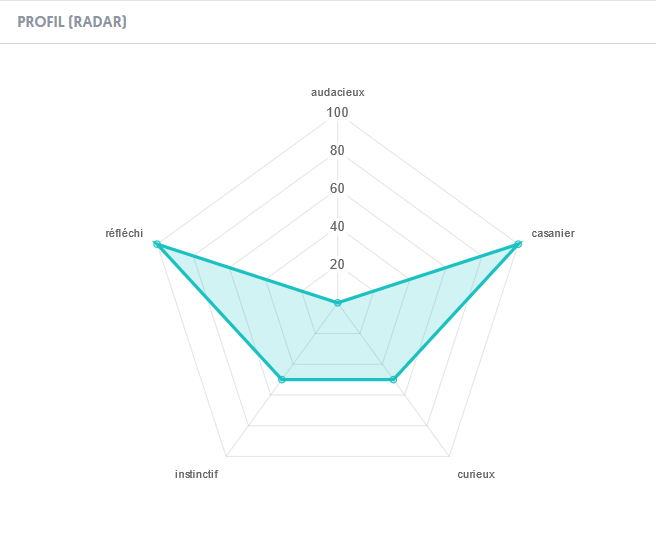
Voici le résultat de la comptabilisation de chaque tag, et donc soft-skill en fonction de la proposition qui a été choisie par l’utilisateur:
Résultat
casanier
instinctif
audacieux
curieux
réfléchi
P1
100%
100%
0%
0%
0%
P2
0%
100%
100%
100%
0%
P3
0%
0%
0%
100%
100%
Illustration avec le soft-skill à choix multiple
On reprend le même exemple que ci-dessus mais en considérant maintenant que la question est à choix multiple.
Résultat
casanier
instinctif
audacieux
curieux
réfléchi
P1
100%
50%
0%
0%
0%
Pourquoi 50% pour le soft-skill « Instinctif » ? Parce qu’il n’a été sélectionné qu’une seule fois sur deux possibles : P1 et P2
Résultat
casanier
instinctif
audacieux
curieux
réfléchi
P1 et P2
100%
100%
100%
50%
0%
Ici, l’utilisateur totalise 100% pour le soft-skill « Instinctif » car toutes les propositions de réponses qui y faisaient référence (P1 et P2) ont été sélectionnées et totalise 50% pour le soft skill « curieux » car il n’a été sélectionné qu’une seule fois sur deux possibles (P2 et P3).
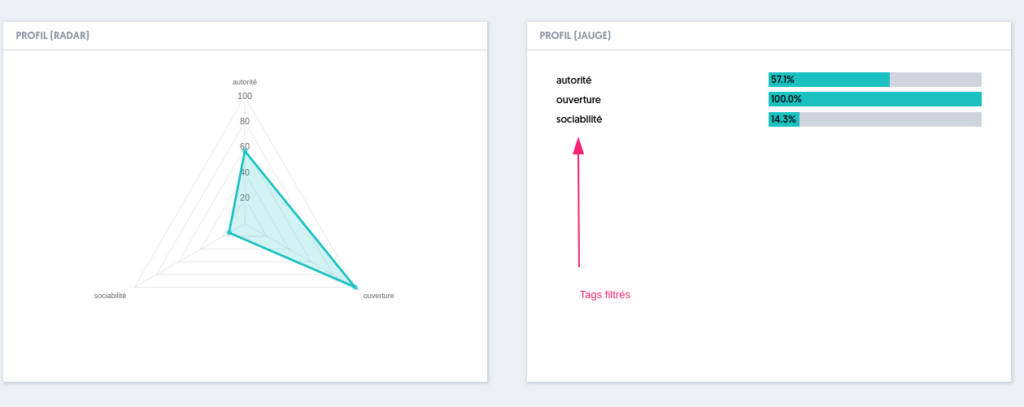
À la fin d’un test qui inclut des questions soft skills, une analyse en forme de graphe radar est présentée à l’utilisateur, si l’option correspondante a été cochée parmi les réglages du questionnaire.
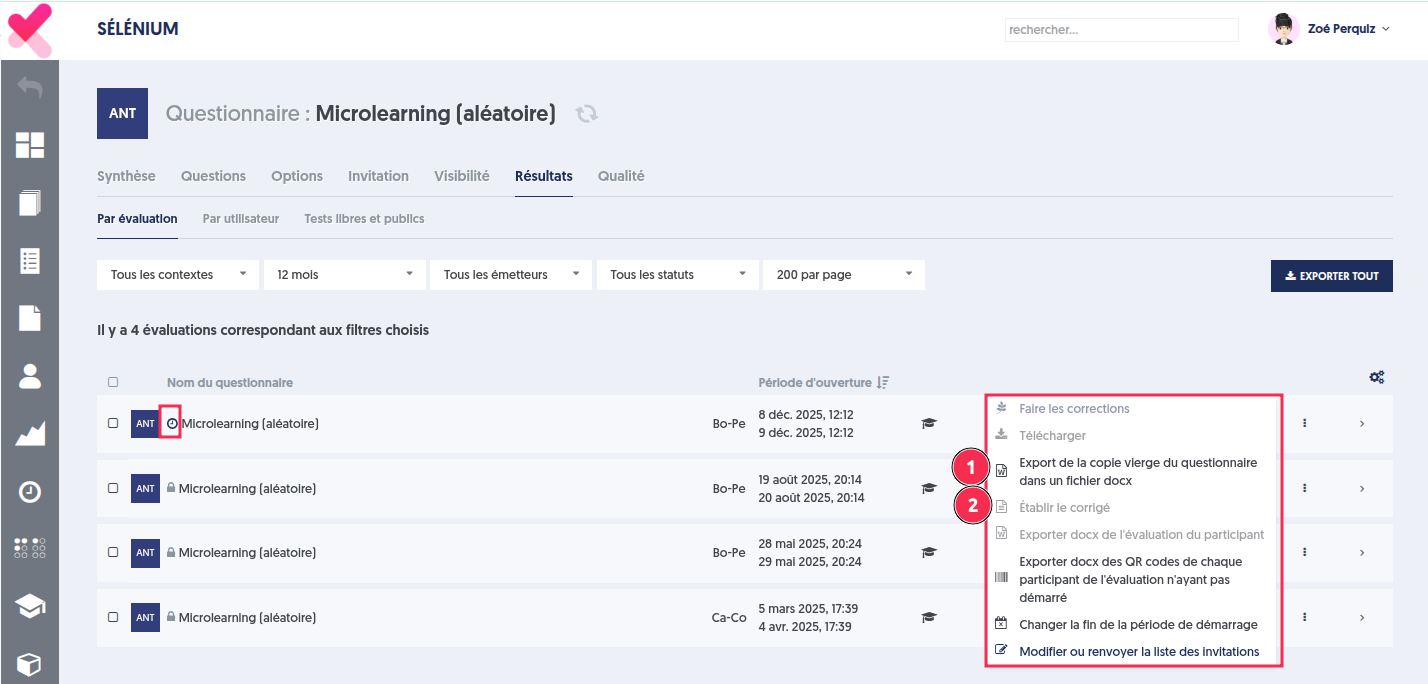
Deux actions de gestion sont possibles au niveau de l’évaluation :
Export de la copie vierge du questionnaire dans un fichier docx.
Établir le corrigé de l’évaluation.
Elles permettent ainsi :
d’accéder immédiatement à une version vierge du questionnaire qui peut être accessible avant le démarrage de l’évaluation.
Et, après l’invitation, d’obtenir le corrigé exact, correspondant au tirage réel des questions présenté au participant.
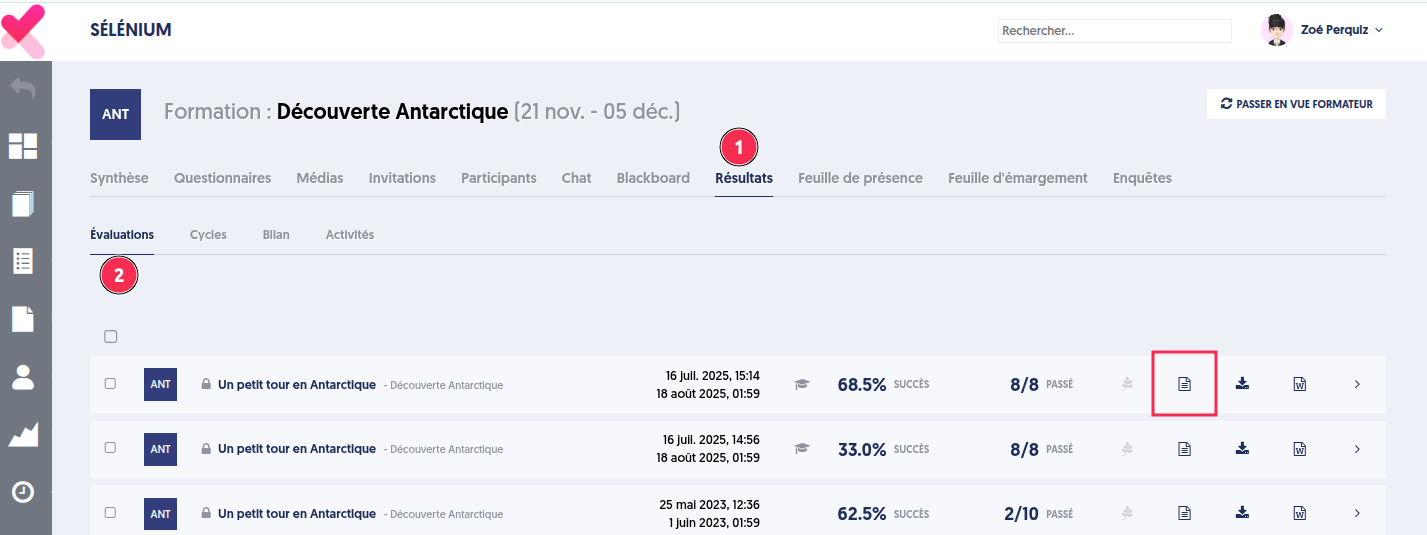
Menu Formation
Dans le menu formation, les résultats des évaluations passées durant la session de formation sont accessibles dans l’onglet “Résultats”, sous-onglet “Évaluations”.
La fonctionnalité d’export du questionnaire corrigé a été également ajoutée sur cette page.
Analyses de la qualité des questions et fiabilité des tests
Chaque fois qu’une personne répond à une question, on obtient de l’information quant à la connaissance de la personne (et c’est en général ce qui nous intéresse le plus), mais on obtient aussi de l’information relativement à la question elle-même. Par exemple, est-ce une question facile (réussie par beaucoup de participants) ou bien difficile (réussie par peu de participants) ?
Mais il y a beaucoup d’autres analyses possibles, et très importantes.
Parlons de la corrélation. D’une manière générale, si l’on a une base de questions portant sur un sujet particulier, disons par exemple le RGPD, on s’attend à ce que “plus une personne connaît bien le RGPD, plus il répond correctement à chacune des questions”. Cela semble très simple et presque évident. Si je considère une question spécifique de ma base, disons la question #23, je m’attends à ce que “plus une personne a un bon score global, plus elle réussit aussi la question #23. Ce n’est pas systématique : il est possible qu’une personne d’un excellent niveau ait échoué à cette question. Mais c’est vrai en général, c’est-à-dire que la probabilité de succès à la question #23 est corrélée à la probabilité de succès au test global.
Si l’on dispose de suffisamment de données, cette corrélation peut se mesurer mathématiquement, et l’on pourra alors se demander, pour chacune des questions, si elle est bien corrélée à la base dans son ensemble. Cette corrélation est une bonne mesure de la qualité de la question, c’est-à-dire de la capacité de cette question de contribuer à la mesure de la connaissance sur cette thématique.
À partir de ce type d’analyse, il est possible de calculer le coefficient “Alpha de Cronbach”, qui est une généralisation du coefficient de Kuder-Richardson, appelé KR-20. On peut dire schématiquement que c’est une mesure d’ensemble de la qualité de la base de questions, autrement dit : plus ce coefficient est élevé, plus les tests utilisant ces questions pourront être fiables. En général, on vise un KR20 supérieur à 70%, et il est courant de parvenir à des valeurs supérieures à 90%.
Une valeur de KR20 inférieure à 70% n’est pas satisfaisante, c’est-à-dire que vos tests ne seront pas d’une fiabilité suffisante. Que peut-on y faire ? C’est assez facile en fait : il suffit de rechercher les questions qui ont une faible corrélation, et soit de les améliorer, soit encore plus simplement de les supprimer.
Les questions qui ont une corrélation négative avec la base dans son ensemble sont vraiment à corriger ou supprimer : ce sont des questions telles que “plus une personne maîtrise bien la connaissance sur cette thématique, moins elle trouve la bonne réponse à cette question”. Autant dire que la question est sans doute soit très mal formulée, soit tout simplement erronée (la bonne réponse n’est pas celle indiquée, les experts connaissent la bonne réponse, donc ils échouent).
À partir de la valeur du KR20, il est possible de déterminer l’erreur standard, c’est-à-dire la marge d’erreur associée aux résultats obtenus à un test utilisant ces questions.
Même avec d’excellentes questions, il est courant que l’erreur standard soit de l’ordre de 5 %, soit environ ±1 point sur une note de 20. Cet indicateur est essentiel : si votre erreur standard est de 15 %, par exemple, un score de 15/20 doit en réalité être interprété comme se situant entre 12/20 et 18/20. Le niveau d’imprécision devient alors préoccupant.
Notons que l’erreur standard dépend à la fois du KR20 et du nombre de questions du test. Plus le test comporte de questions, plus l’erreur standard diminue. C’est pourquoi cet indicateur est surtout pertinent au niveau d’un questionnaire donné, et non à l’échelle d’une base complète de questions.
Retenez surtout ceci : les analyses statistiques de qualité font intervenir des calculs un peu complexes, mais vous n’avez pas à vous en préoccuper, il vous suffit de regarder les résultats et les recommandations qui vous sont présentés.
Ces analyses sont offertes par la plateforme Experquiz depuis des années, mais elles ont été sensiblement améliorées, et rendues plus performantes, dans cette version.
Pour accéder aux analyses qualité, il vous faut en premier lieu activer la fonctionnalité dans les réglages de votre entreprise (Onglet “Paramètres”, section “Bases”).
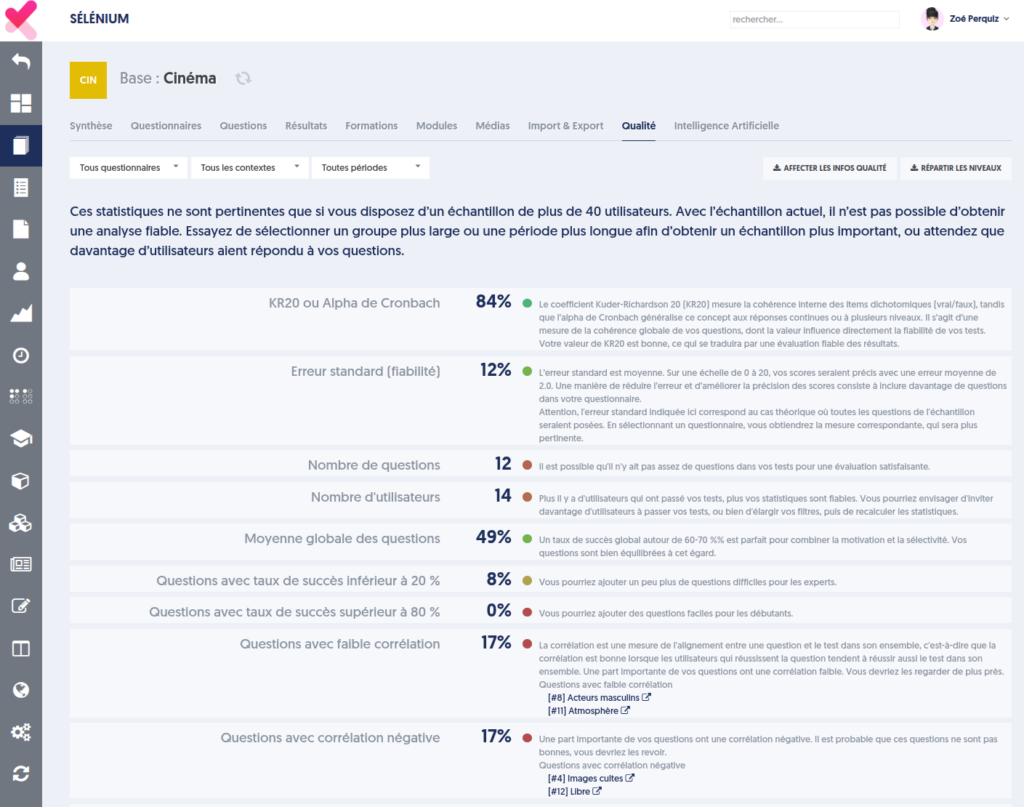
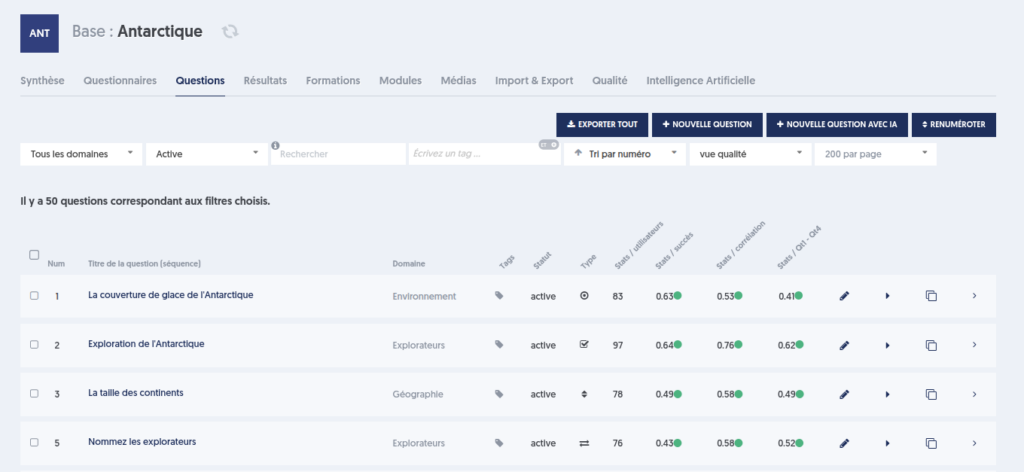
Au niveau de chacune de vos bases de questions, vous disposez alors d’un onglet “Qualité”, qui se présente comme ceci:
Vous disposez des filtres suivants :
Soit tous les questionnaires, soit l’un seulement des questionnaires de la base.
Vous pouvez choisir un contexte de test particulier, par exemple si vous pensez que les résultats relevant d’une évaluation sont plus pertinents que les résultats en tests libres.
Vous pouvez sélectionner une période spécifique, pour ne considérer que les résultats de cet intervalle.
La page présente ensuite un tableau d’indicateurs, et pour chacun des indicateurs, une pastille de couleur indiquant dans quelle mesure la valeur est statisfaisante, et un commentaire extensif accompagné de recommandations.
Si votre échantillon (les tests correspondant à vos filtres) porte sur moins de 40 utilisateurs, un avertissement est présenté en haut de page, vous mettant en garde sur la fiabilité des analyses. Ce type d’analyse n’est vraiment pertinent que si plus de 40 utilisateurs ont répondu à vos questions.
Les indicateurs sont les suivants :
Alpha de Cronbach / KR20 : voir l’explication au chapitre précédent.
Erreur standard : Voir l’explication au chapitre précédent. Rappelons qu’elle n’a vraiment de sens que pour un questionnaire donné.
Nombre de questions : pour des scores fiables, il faut que vos tests incluent un nombre suffisant de questions, si possible au moins 30 questions. Sur des tests de moins de 20 questions, les aléas sont plus importants, et l’erreur standard sera plus importante.
Nombre d’utilisateurs : comme énoncé en préambule, ces analyses requièrent au moins 40 utilisateurs.
Moyenne globale des questions : on considère qu’un taux de succès moyen autour de 60 à 70% est idéal pour combiner motivation (le participant est motivé par ses succès) et sélectivité (tous les participants ne réussissent pas toutes les questions). Mais cet indicateur n’a pas une importance critique.
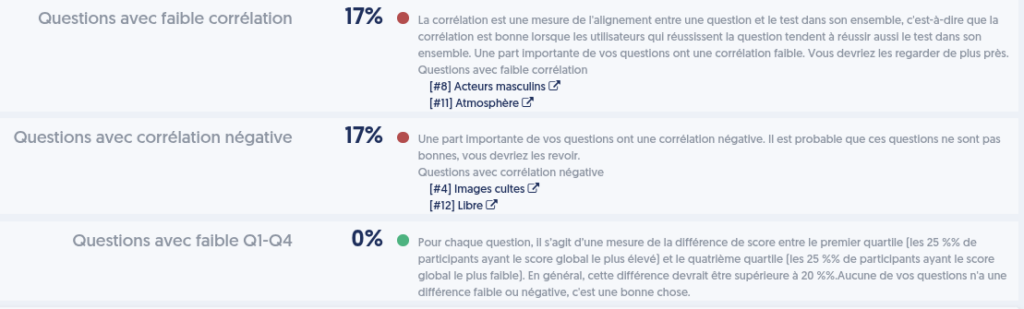
Questions avec taux de succès inférieur à 20 %
Questions avec taux de succès supérieur à 80 %
Questions avec faible corrélation : voir plus haut, l’explication relative à la notion de corrélation. Une question de faible corrélation est une question telle que “les participants les plus experts ne répondent pas mieux à cette question que les participants les plus faibles”. La question n’est peut-être pas erronée, mais elle ne semble pas mesurer la même connaissance que les autres questions.
Questions avec corrélation négative : comme vu plus haut, les questions à corrélation négative sont vraiment un souci, il faut absolument s’en préoccuper car elles dégradent la qualité de vos tests.
Questions avec faible Q1-Q4 : on fait appel ici à une notion qui ressemble à la corrélation, mais se calcule d’une manière un peu différente.
Pour ces trois derniers indicateurs, le tableau présente la liste complète des questions concernées, avec un lien permettant de modifier la question dans un nouvel onglet.
Les graphiques
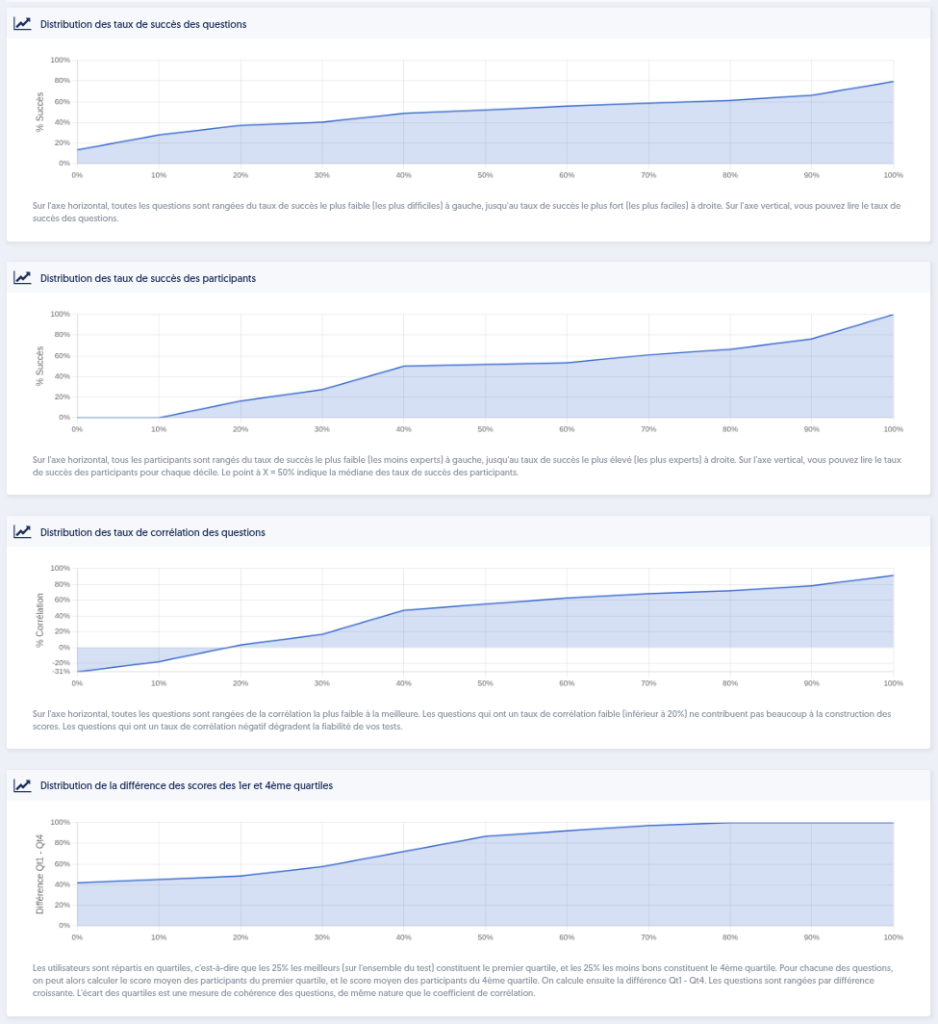
La partie suivante de la page présente 4 graphiques :
La distribution du taux de succès des questions : sur l’axe horizontal, toutes les questions sont rangées du taux de succès le plus faible (les plus difficiles) à gauche, jusqu’au taux de succès le plus fort (les plus faciles) à droite. Sur l’axe vertical, vous pouvez lire le taux de succès des questions. Idéalement, c’est une courbe qui pourrait être une droite conduisant de 0% à gauche jusqu’à 100% à droite. Il n’y a pas véritablement de mauvaise configuration, mais si par exemple la courbe atteint les 100% dès le milieu, c’est-à-dire que la moitié de vos questions ont un taux de succès de 100%, cela signifie sans doutes qu’il manque des questions plus difficiles, car toutes ces questions que tout le monde réussit n’apporte pas tellement à vos scores.
La distribution des taux de succès des participants : sur l’axe horizontal, tous les participants sont rangés du taux de succès le plus faible (les moins experts) à gauche, jusqu’au taux de succès le plus élevé (les plus experts) à droite. Sur l’axe vertical, vous pouvez lire le taux de succès des participants pour chaque décile. Le point à X = 50% indique la médiane des taux de succès des participants.
La distribution des taux de corrélation des questions : sur l’axe horizontal, toutes les questions sont rangées de la corrélation la plus faible à la meilleure. Les questions qui ont un taux de corrélation faible (inférieur à 20%) ne contribuent pas beaucoup à la construction des scores. Les questions qui ont un taux de corrélation négatif dégradent la fiabilité de vos tests. Sur l’image ci-dessous, on voit que quelques questions ont une corrélation négative.
La distribution de la différence des scores des 1er et 4ème quartiles : les utilisateurs sont répartis en quartiles, c’est-à-dire que les 25% les meilleurs (sur l’ensemble du test) constituent le premier quartile, et les 25% les moins bons constituent le 4ème quartile. Pour chacune des questions, on peut alors calculer le score moyen des participants du premier quartile, et le score moyen des participants du 4ème quartile. On calcule ensuite la différence Qt1 – Qt4. Les questions sont rangées par différence croissante. L’écart des quartiles est une mesure de cohérence des questions, de même nature que le coefficient de corrélation.
La matrice de corrélation et les clusters de questions
En bas de la page, vous trouverez la matrice de corrélation complète, qui présente, sous la forme de petits carrés colorés, la corrélation entre chaque couple de questions de la base.
Les cases de couleur verte, plus ou moins intense, représentent un couple de questions qui ont une corrélation positive. Cela signifie que si les personnes réussissent la première question, il est probable qu‘ils réussissent également la seconde. Plus la couleur verte est intense, plus la corrélation est forte.
Réciproquement, les cases de couleur rouge représentent un couple de question qui ont une corrélation négative : lorsque l’on réussit à la première question, alors il est probable que l’on échoue à la seconde.
Sur la base de ces corrélations, on peut construire ensuite des groupes de questions qui sont corrélées entre elles, des clusters. Lorsqu’une personne réussit l’une des questions du clusters, il est probable (très probable ou un peu probable), qu’elle réussisse également les autres questions du cluster.
Cela ne doit pas amener à penser que les questions du cluster sont égales et que l’une seulement pourrait suffire. D’abord la corrélation ne prouve pas que la connaissance mesurée est la même, et de plus il est toujours bon d’aborder une notion sous différents angles, avec des questions variées.
Les boutons d’action
En haut de cette page qualité, vous disposez de deux boutons d’action. Ils ne sont actifs que si l’échantillon inclut suffisamment de participants pour permettre des analyses satisfaisantes.
le bouton AFFECTER LES INFOS QUALITÉ : ce bouton attache les informations calculées ici à chacune des questions de la base. Ces informations peuvent ensuite être visualisées dans la liste des questions de la base, en choisissant la “vue qualité”. Ainsi vous disposerez, pour chaque question, de son taux de succès moyen, sa corrélation à l’ensemble de la base, l’écart des premiers et quatrième quartile.
le bouton RÉPARTIR LES NIVEAUX : ce bouton permet de redéfinir le niveau de difficulté de chacune des questions de la base. Les questions sont rangées de la plus facile (plus haut taux de succès) à la plus difficile (plus faible taux de succès), les 20% de questions les plus faciles reçoivent la valeur 1 pour leur niveau. Les 20% suivants auront la valeur 2. Et ainsi de suite jusqu’aux 20% les plus difficiles, qui auront la valeur 5.
C’est un outil très utile pour affecter un niveau de difficulté fiable. En effet, les contributeurs ne peuvent pas déterminer avec certitude si une question est de difficulté 2 ou bien 3. Avec cette fonctionnalité, vous avez une mesure de la difficulté basée sur les réponses de vos utilisateurs.
Dans un questionnaire, il peut y avoir deux types de tags :
Les tags de questions non soft skills
Les tags des réponses de questions soft-skills
Les tags de questions permettent de construire des scores par tag, qui donneront une analyse fine des résultats. Ils permettent aussi de retrouver des questions en les filtrant par tag.
Les tags de réponse, qui ne concernent que les questions soft-skills, ont un usage un peu différent: ils permettent d’élaborer des scores de soft-skills, chaque réponse choisie contribue à renforcer le score sur le ou les tags que portait cette réponse.
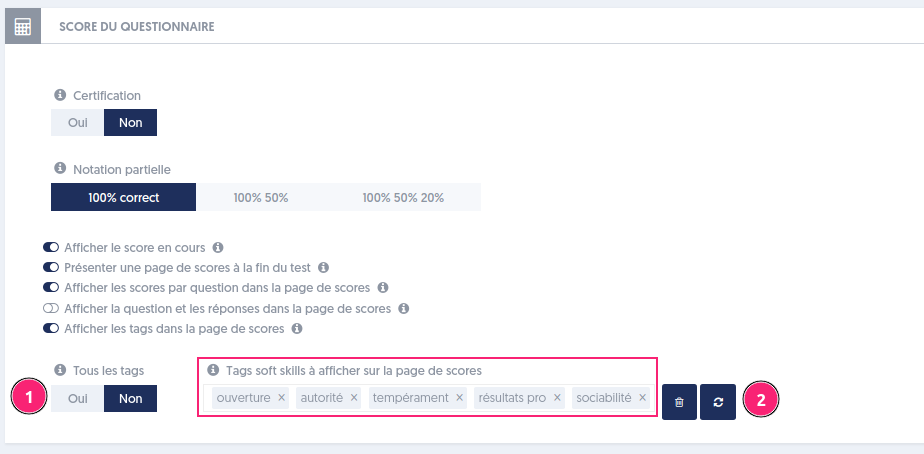
Dans les options du questionnaire, il était possible déjà de sélectionner les tags de questions à afficher dans la page de résultats. Cette fonctionnalité est maintenant proposée pour les tags des questions soft skills.
Il faut choisir l’option “Afficher les tags dans la page de score” puis cocher “Non” [1] pour l’option “Tous les tags” et enfin choisir les tags à afficher. Deux boutons [2] permettent de supprimer tous les tags (poubelle) ou de les réinitialiser.
Si on restreint la liste des tags aux 3 tags suivants :
La page de scores ne présente que cette liste restreinte.
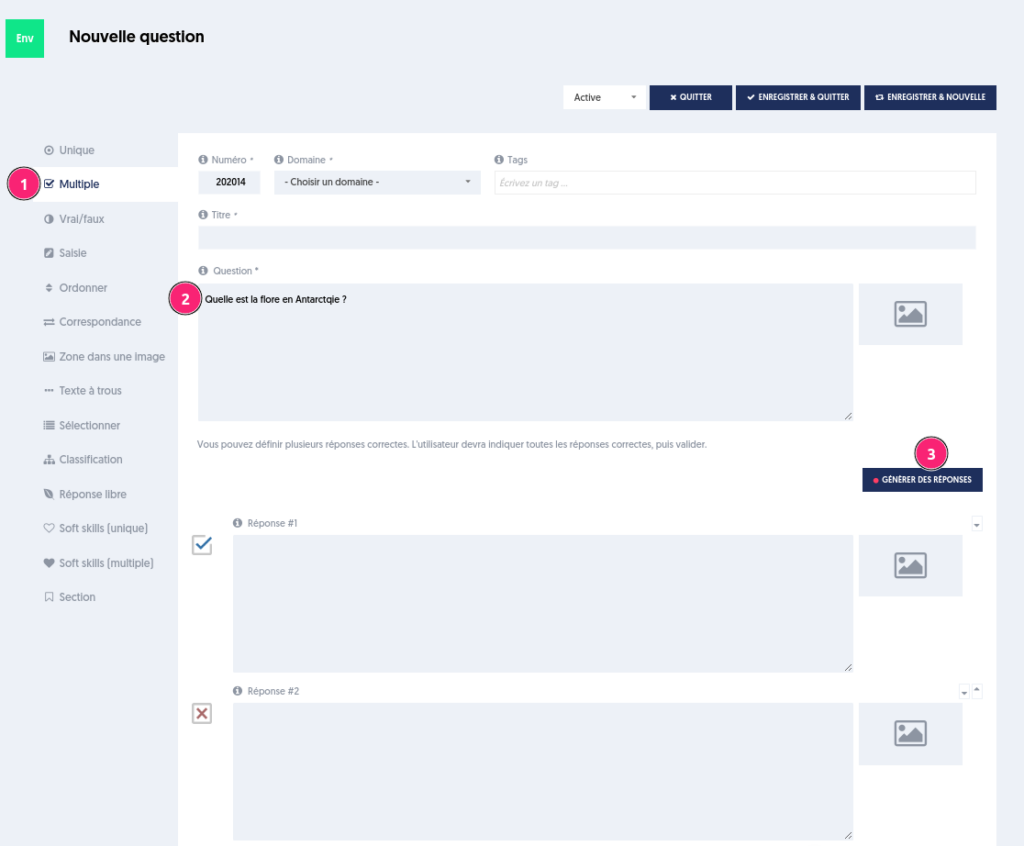
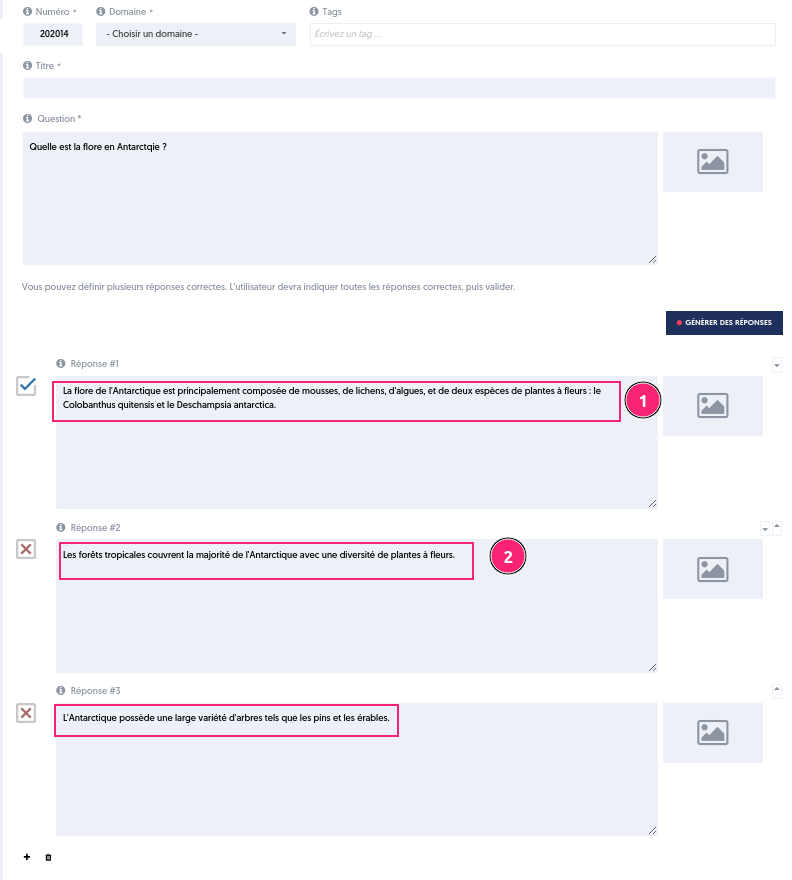
La conception de questions est souvent chronophage. Écrire la question avec sa réponse correcte est relativement facile pour un expert, mais la rédaction de distracteurs (réponses fausses) est un exercice difficile. La fonction de génération de réponses assistée par l’IA permet d’accélérer cette étape.
Lorsque vous rédigez une nouvelle question de type unique ou multiple [1], vous pouvez maintenant écrire le texte de la question [2] puis cliquer sur le bouton Générer des réponses [3].
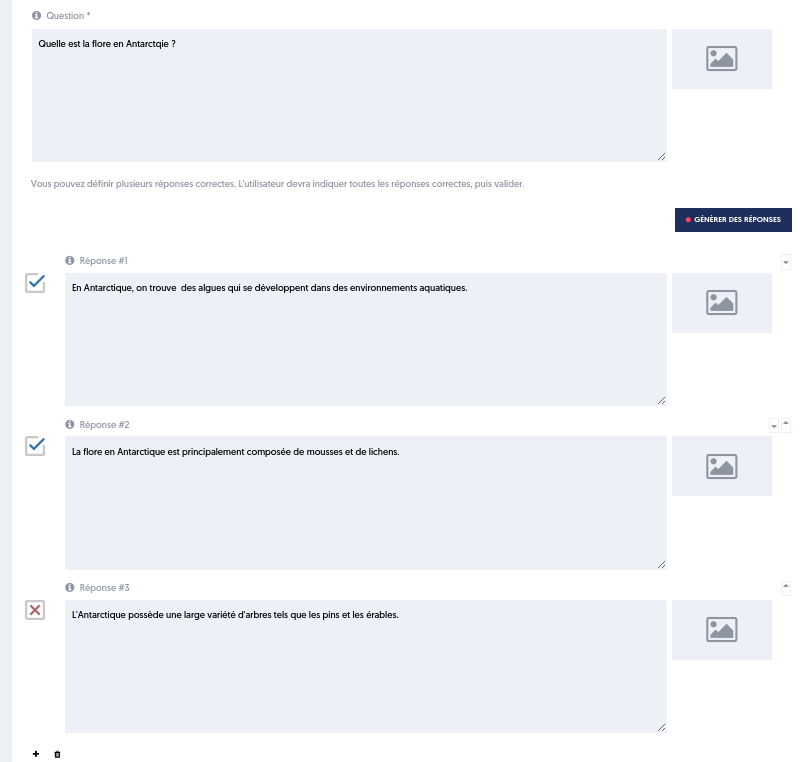
Après recherche, des réponses sont proposées.
Si dans les réponses proposées par l’IA, certaines correspondent à notre attente et d’autres pas, alors il suffit de supprimer celles qui ne conviennent pas et de demander de générer à nouveau des réponses. L’IA conservera ce qui est déjà complété et fera de nouvelles propositions pour les réponses vides.
Lorsque les réponses conviennent, on peut enregistrer la question.
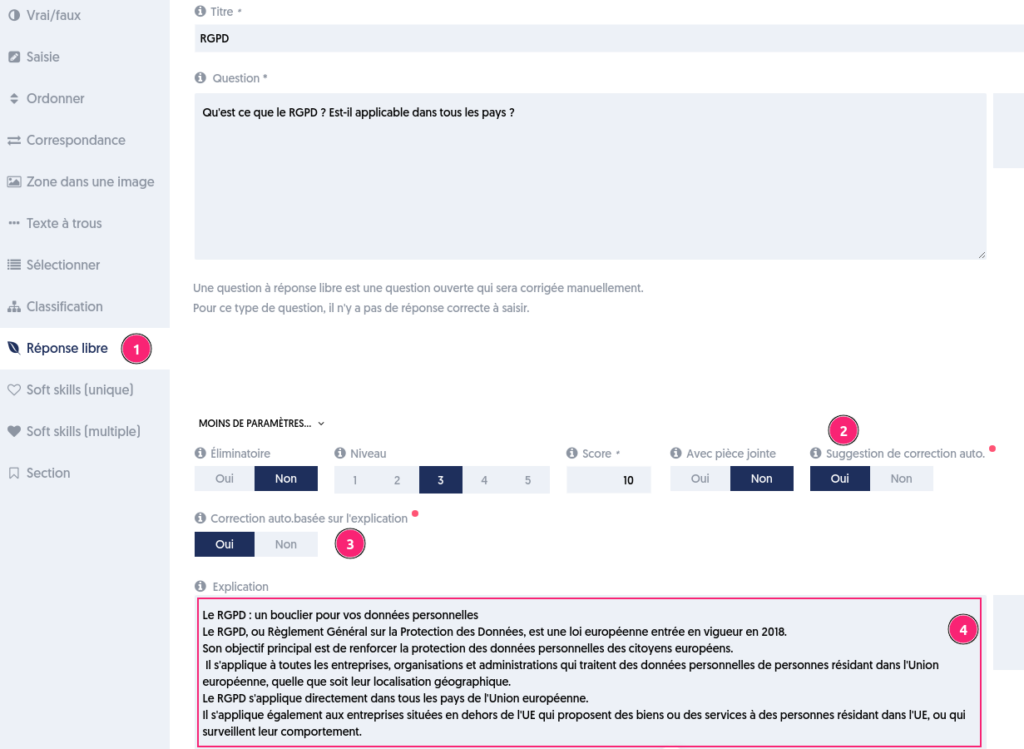
ExperQuiz propose un type de question qui est corrigée par un formateur de façon asynchrone : c’est la question libre. Le correcteur peut rédiger une appréciation et affecter une note qui est réintégrée dans la note globale de l’évaluation.
ExperQuiz utilise l’intelligence artificielle pour analyser le texte proposé comme réponse et pour suggérer des commentaires et une note.
Le correcteur peut accepter tout ou partie des suggestions et conserver la note s’il juge que les suggestions sont pertinentes. Notez qu’il s’agit seulement d’une aide proposée au correcteur qui doit toujours définir son commentaire ainsi que la note à attribuer, dont il est au final le seul responsable.
Chaque suggestion est uniquement basée sur le texte de la question et celui de la réponse. Aucune image / média / pièce-jointe n’est prise en compte lors de la génération de la correction de l’attribution de la note.
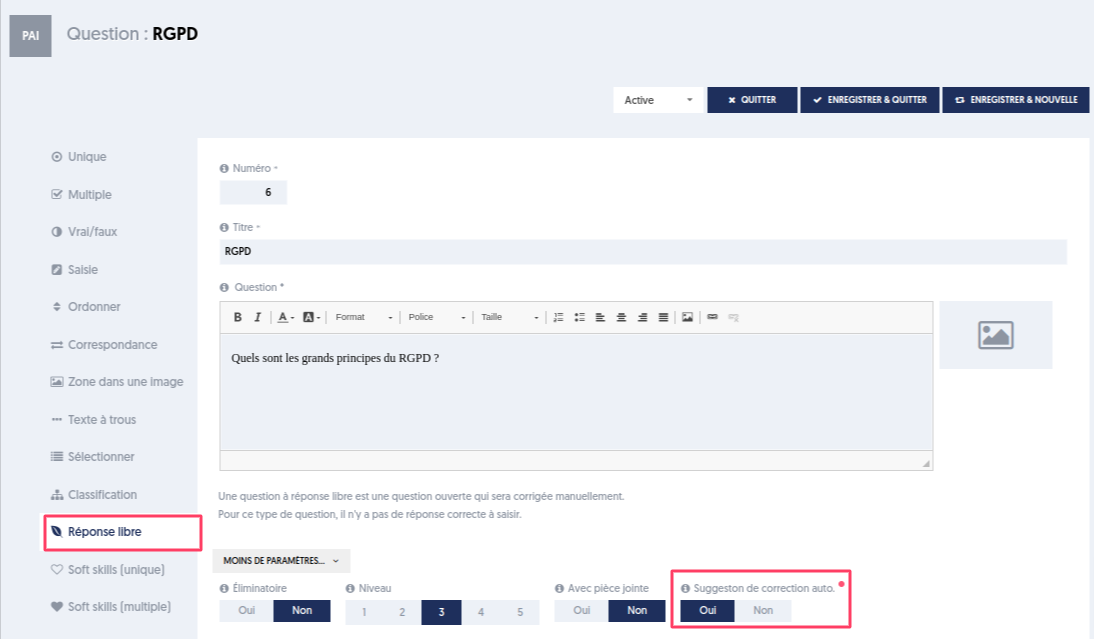
Pour activer cette fonctionnalité, il faut préciser dans les paramètres de la question qu’il y aura une demande d’aide à la correction.
Lorsque l’évaluation est terminée, la correction automatique est appelée. Cela peut prendre quelques minutes. Ce qui n’empêche pas le correcteur d’aller voir les réponses et de commencer son analyse.
Il est impératif de vérifier la qualité des suggestions en fonction de la réponse de l’utilisateur.
Notez que, de par sa construction, l’IA sera probablement moins pertinente sur des sujets d’actualité récents ou non accessibles au grand public.
Considérant la question libre [1] suivante :
Dans le panneau “PLUS DE PARAMÈTRES”, il est possible d’indiquer que l’on souhaite la correction assistée par l’IA [2] en se basant sur l’explication [3] qui se trouve dans le bloc « Explication » de la question [4].
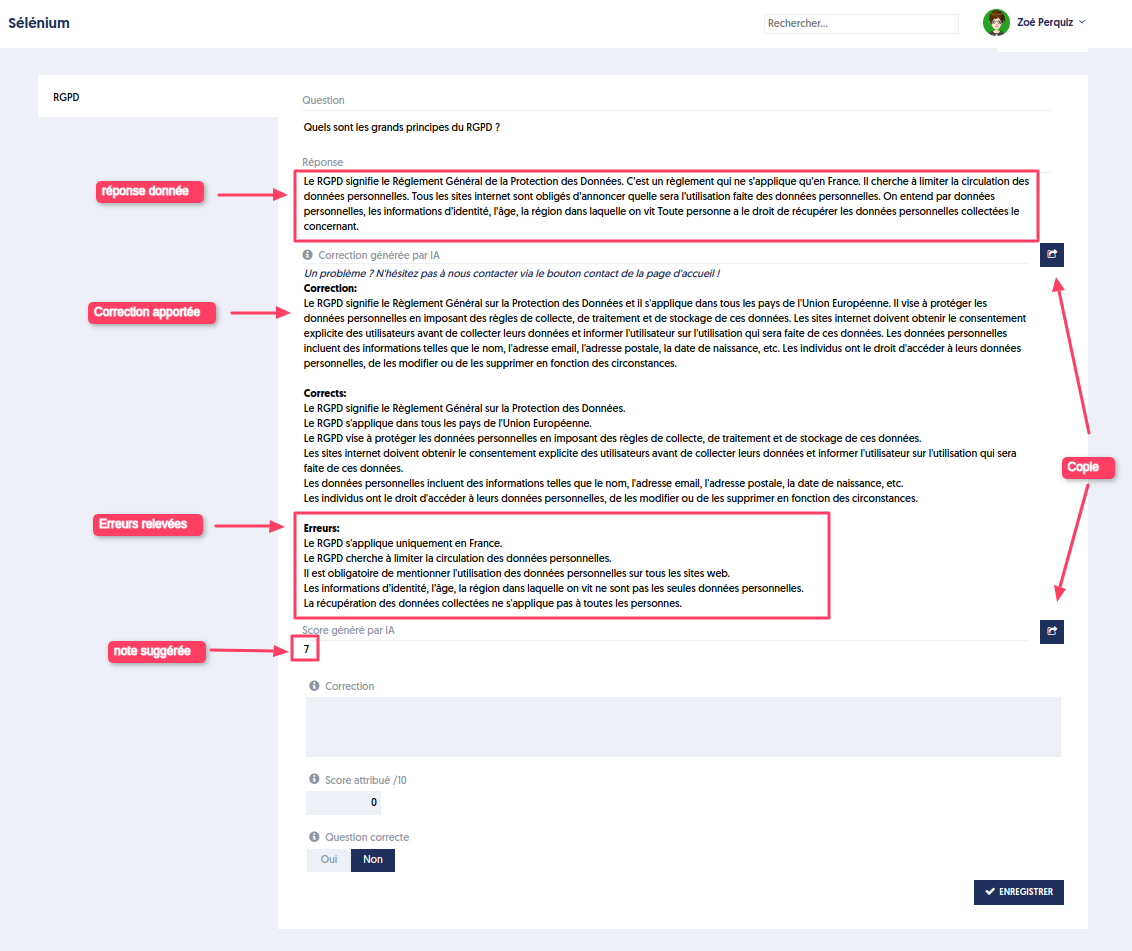
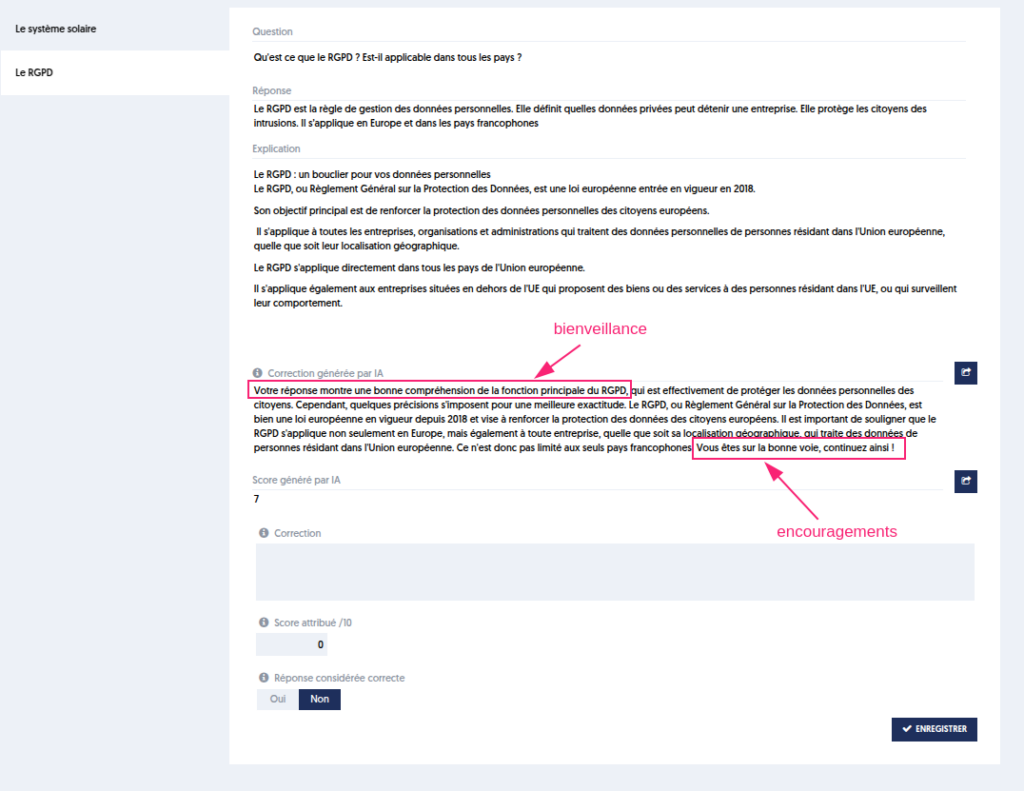
Lorsqu’une évaluation est passée, le correcteur pourra consulter la réponse donnée et l’explication fournie par l’IA comme suggestion de correction.
La partie générée par l’IA comporte une rédaction de la correction avec relevé des points corrects et des erreurs. Elle propose également une note.
Le bouton 1 permet de recopier la correction suggérée par l’IA dans la partie “Correction” du correcteur qui pourra l’adapter selon son jugement.
Le bouton 2 permet de recopier la note proposée par l’IA.
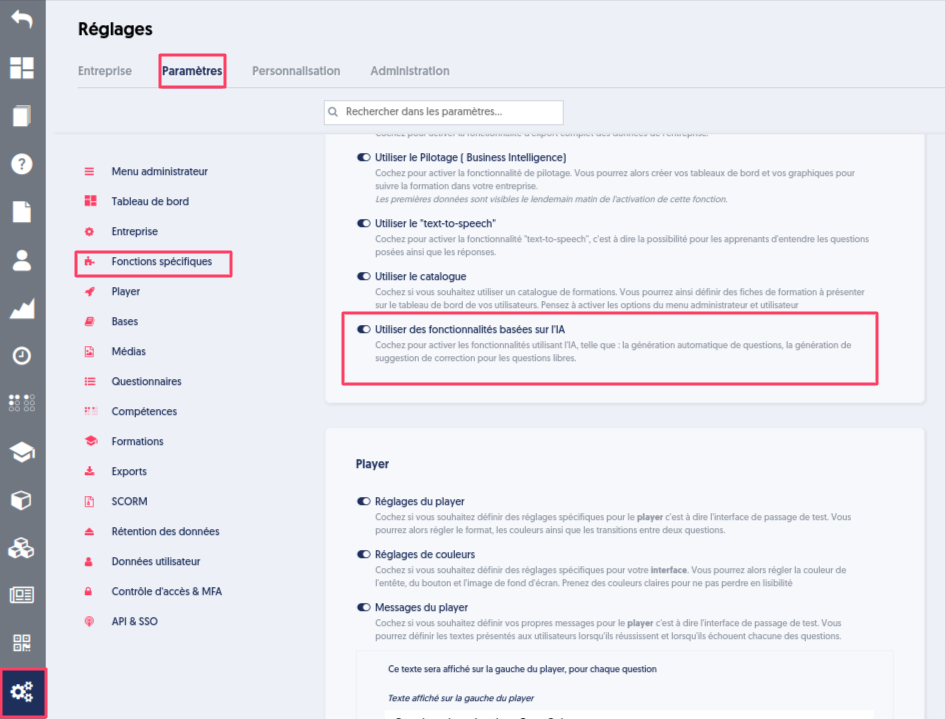
Activer la fonctionnalité
Pour activer les fonctionnalités qui utilisent l’intelligence artificelle, il faut cocher l’option “Utiliser des fonctionnalités sur l’IA” dans les réglages de l’entreprise.
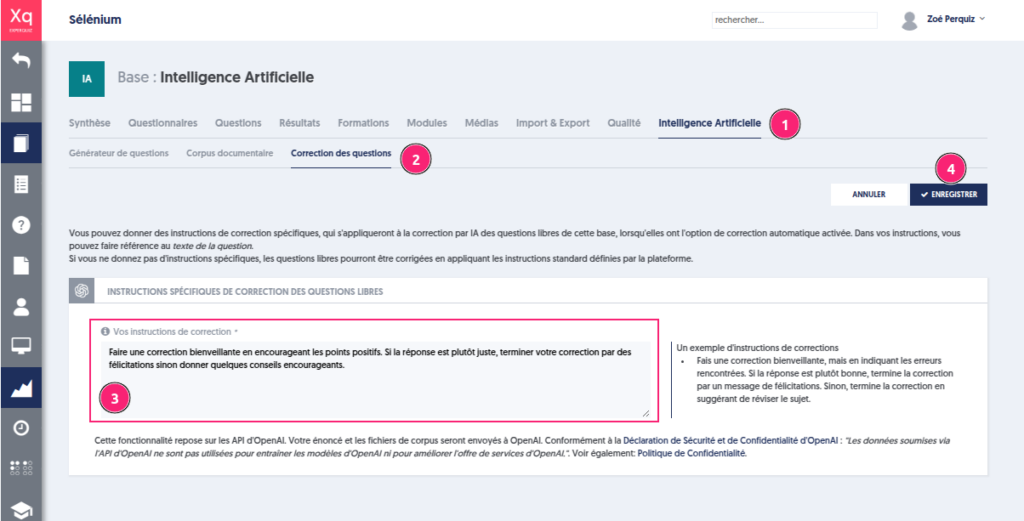
Personnaliser l’assistant de correction
Vous pouvez personnaliser votre assistant et ainsi donner des instructions de correction spécifiques, qui s’appliqueront à la correction par IA des questions libres de cette base, lorsqu’elles ont l’option de correction automatique activée.
Pour cela, rendez vous sur la page “Intelligence Artificielle” dans l’onglet “Correction des questions”.
Par exemple vous pouvez indiquer :
Faire une correction bienveillante en soulignant les points positifs. Si la réponse est plutôt juste, terminer votre correction par des félicitations sinon donner quelques conseils encourageants.
Si vous ne donnez pas d’instructions spécifiques, les questions libres pourront être corrigées en appliquant les instructions standard définies par la plateforme.
La génération de questions n’est plus limitée aux seules connaissances “universelles” déjà ingérées par OpenAI, mais peut cibler également des connaissances propres à l’entreprise. Vous pouvez ajouter à votre corpus un règlement intérieur, la documentation d’un produit, le support d’une formation, etc.
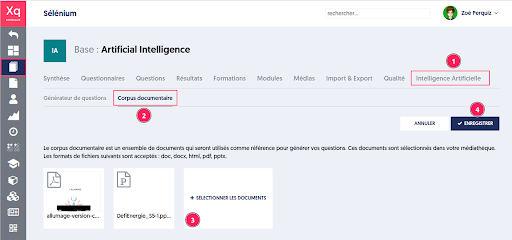
Choix du corpus documentaire
L’administrateur peut définir son propre corpus documentaire, à partir duquel les questions seront générées. Cela permet de personnaliser et de circonscrire les sources d’informations sur lesquelles l’IA générative s’appuiera pour créer les nouvelles questions.
Pour cela :
Aller sur la page “Intelligence Artificielle” de la base choisie.
Puis dans l’onglet “Corpus documentaire”.
Sélectionner les documents au format doc, docx, html, pdf, pptx. Les documents sont choisis parmi ceux de votre médiathèque, mais vous pouvez en importer de nouveaux si besoin.
Enregistrer la sélection de documents avant de quitter la page.
Génération des questions
La génération de questions se paramètre en s’appuyant ou non sur tout ou partie des documents.
Pour cela :
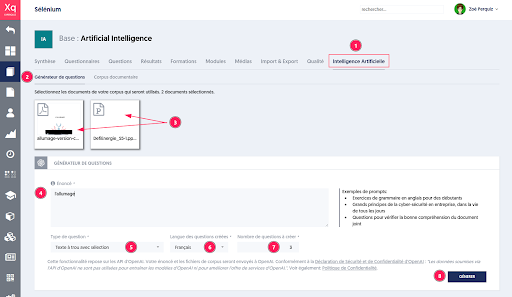
Aller sur la page “Intelligence Artificielle” de la base choisie
Puis sur l’onglet “Générateur de questions”.
La liste des documents du corpus est présentée en haut de page. Sélectionner le ou les documents à utiliser pour la création de question. Cliquer sur les documents pour les sélectionner ou les dé-sélectionner.
Donner l’énoncé ou le sujet, qui peut être un chapitre ou le titre du document
Choisir le type de question souhaité
Sélectionner la langue
Indiquer le nombre de questions
Démarrer la génération en cliquant sur le bouton “GÉNÉRER”
Validation des questions générées
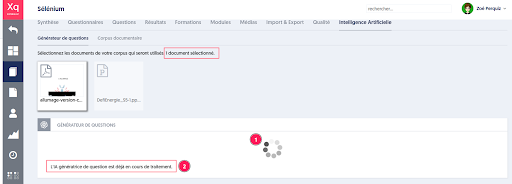
La génération démarre, un message indique qu’elle est en cours [1], [2].
Les questions sont générées au fil de l’eau et l’administrateur peut :
Accepter la question en mode brouillon afin de l’adapter
Valider la question qui rejoint l’ensemble des questions qui peuvent composer un questionnaire
Rejeter la question
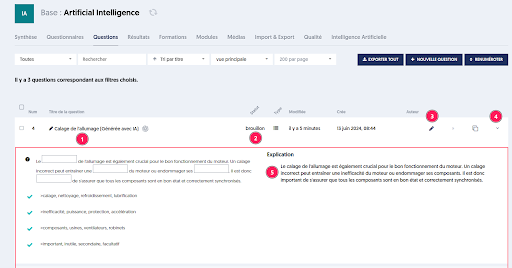
On retrouve la question acceptée [1] dans la liste des questions de la base, elle est soit active, soit en mode brouillon [2].
Pour l’intégrer dans les questionnaires, l’administrateur peut éditer la question [3] ou consulter son contenu en ouvrant le panneau de détail [4].
L’IA a également généré une explication qui sera utilisée dans le feedback donné à l’utilisateur pendant son test si cette option a été choisie.
RGPD, Sécurité et confidentialité
Cette fonctionnalité repose sur les API d’OpenAI. Votre énoncé et les fichiers de corpus seront envoyés à OpenAI.
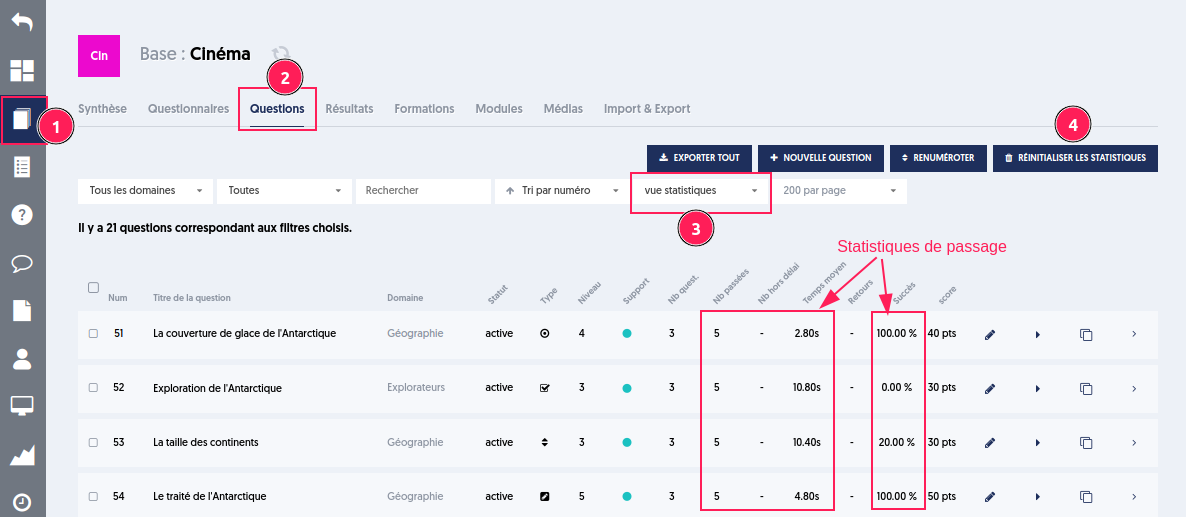
ExperQuiz présente une vue statistique dans la page des questions. On peut ainsi consulter le nombre de fois où une question a été soumise, son taux de réussite, le temps moyen passé pour y répondre, le nombre de hors délai (lorsque le participant n’a pas eu assez de temps pour y répondre).
Pour cela, il faut choisir sa base [1], aller sur l’onglet des questions [2] et filtrer sur la vue statistiques [3].
Il s’agit d’un historique qui cumule les données dans le temps.
Il est possible de réinitialiser ces statistiques en cliquant sur le bouton “Réinitialiser les statistiques” [4]
Un nouveau type de question est proposé : il s’agit de la question “section”, qui permet de structurer un questionnaire en groupant les questions par section, les sections étant séparées par une sorte d’intercalaire.
Définir une question de type section
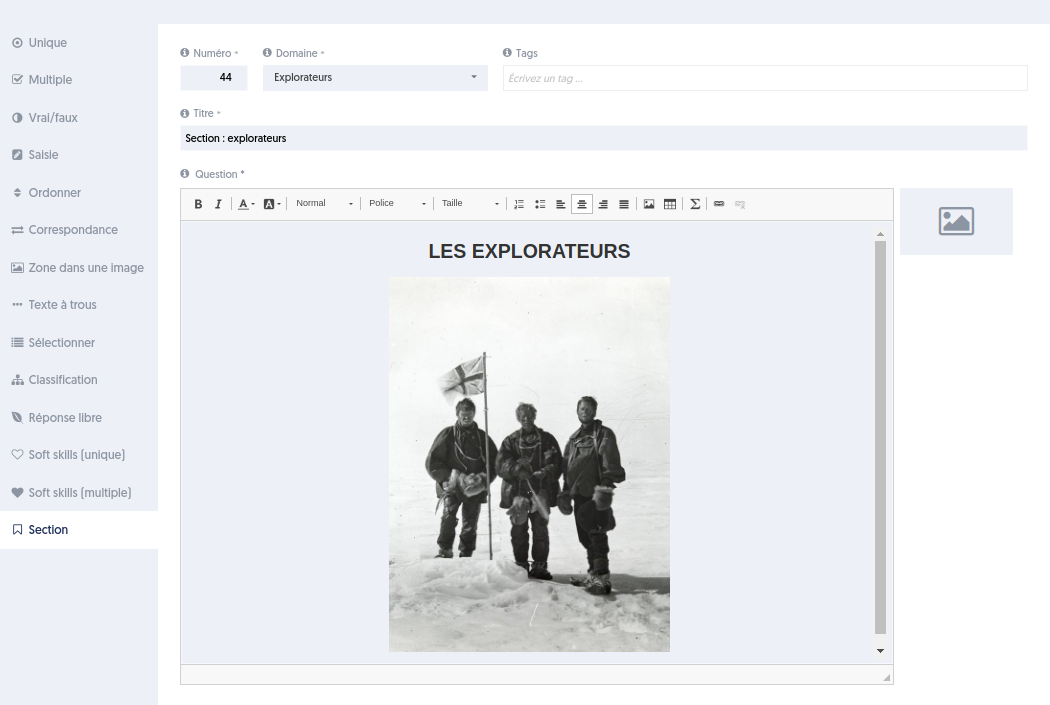
La question “section” permet, comme son nom l’indique, de créer des sections dans un questionnaire. C’est une “pseudo-question”, dans le sens où elle ne présente pas de réponses proposées, et elle ne sera pas notée. Son rôle est de séparer des groupes de questions à l’intérieur d’un même questionnaire.
Comme toute question, elle a un titre [2] et un énoncé [3] qui peut être du texte et/ou un média [4]. Mais elle n’a pas de réponses à proposer.
Si la base thématique a défini des tags, des séquences, explication ou règle, ces informations peuvent être également renseignées dans la question section.
Exemple
Un questionnaire peut contenir plusieurs sections pour séparer, par exemple, les sous thématiques.
Dans l’exemple ci-dessous, le questionnaire contient deux questions sections (#44 et #45). Les questions sections permettent d’apporter des explications, ou de situer le contexte des questions à venir, avant de commencer une nouvelle série de questions.
Paramétrage du test
Lorsque le test commence, la question section se présente comme une question normale avec un chrono si le paramétrage du test l’a prévu ainsi.
Un point important: si le paramétrage du test prévoit que les questions sont mélangées, alors le mélange se fera en respectant les sections c’est-à-dire que les questions seront mélangées entre les sections, mais ne changeront pas de section.
Cas particulier du questionnaire dynamique
Le questionnaire dynamique est un questionnaire dont les questions sont choisies aléatoirement en respectant certains critères comme:
Le niveau de difficulté
Le nombre de questions par domaine (sous thématique)
Le nombre de questions indiqué par domaine inclut les questions de type “section”.
Les questions de type « section » ne seront pas choisies dans les questionnaires dynamiques, sauf si elles font partie d’une séquence de questions qui est présente dans le tirage de questions. En effet, dans le tirage aléatoire, une séquence de questions est incluse dans son intégralité.
Résultats du test
La page de score présente les réponses aux questions données en matérialisant les sections présentes dans le test.